
Today (April 6, 2022) Google announced BigLake. A new service in the Google Cloud Platform (GCP) that enables users to unify data lakes and warehouses, control access on a row and column level and use the GCP native tool BigQuery – as well as open-source processing services such as Spark (via BigQuery Storage Read API) – to analyze that data.
BigLake is built on BigQuery (BQ) and allows you to seamlessly analyze files of familiar formats (CSV, JSONL, Avro, Parque and ORC) that can be distributed in different cloud storage systems (GCP - cloud storage, AWS S3, Azure - Blob Storage) all from a centralized location. This allows for a single source of data “truth” across multiple cloud platforms without the need to duplicate or copy your data. As mentioned above, BigLake can also take advantage of BigQuery’s row- and column-level security, enabling you to share sensitive files the way you want to.
Use Case
As a prerequisite, to start using BigLake features in your BigQuery you will first need to enable the Bigquery Connection API.
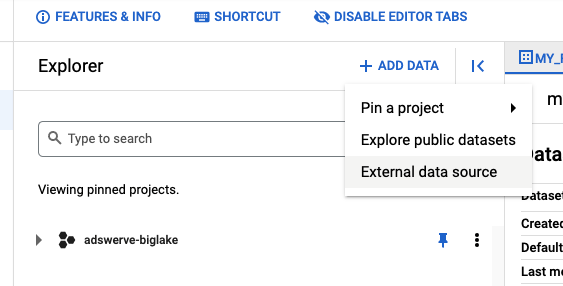
Once enabled, head over to your BigQuery services and add a new External data source by selecting the “+ ADD DATA” button and clicking on the External data source.
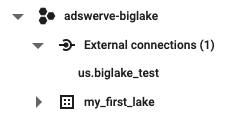
Select “Cloud Resource (for BigLake tables)” as a Connection Type. Give it a unique connection id and optionally a friendly name, data location and a description. If you wanted to connect to Amazon S3 or Azure Blob Storage you would have to select a “via BigQuery Omni” connection type.

Once the new external data source is added you should be able to see it in your left menu under “External connections”
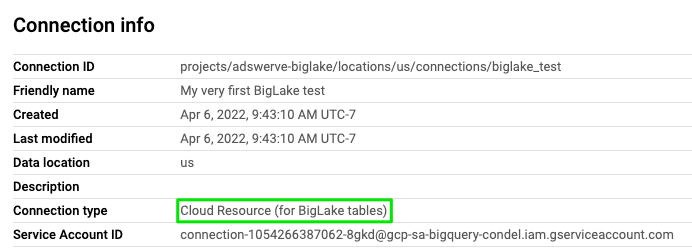
Navigate to the new connection (in our case us.biglake_test in external connections) and copy the service account information. This service account is used to access data in cloud storage. Head over to IAM & Admin and add the service account as a “Storage Object Viewer” to your project. This will allow the connection to read data from your Cloud Storage buckets.
At this point, you can go ahead and create your first BigLake table that will read data from your cloud storage bucket. To create a new table, navigate to an existing dataset (or create a new one) and click on Create Table. Under “Create table from” select “Google Cloud Storage”. Here you could also select Amazon S3 or Azure Blob Storage to read files from an external cloud provider.

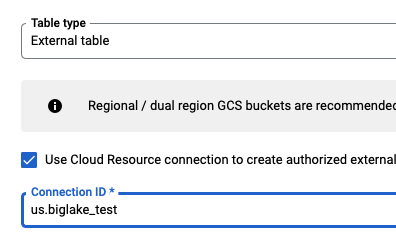
After providing the location of the file, its format and desired destination, make sure to select table type as External table, which will let BigQuery know not to import the file, but instead read it from the external data source. Then tick the checkbox in front of “Use Cloud Resource connection to create authorized external table” which will bring up the Connection ID drop-down and select the connection created in the previous step.
Complete the rest of the options (Schema, Partition/Cluster settings, advanced options) and click on “CREATE TABLE”.
The table should now be available for you to query. These tables are read-only (no DML statements) and can be used in queries with BigQuery's native tables. You can also go ahead and start adding access controls to these tables and take full advantage of BigLake’s capabilities.
Overview
Overall BigLake is a great solution for any organization that works with structured data, potentially across multiple cloud providers and wants to enable their analysts and data scientists to access and work with that data in familiar processing environments.
As always, feel free to contact our team with any questions.
Sources
- https://cloud.google.com/bigquery/docs/biglake-intro
- https://cloud.google.com/bigquery/docs/biglake-quickstart
- https://cloudonair.withgoogle.com/events/summit-data-cloud-2022/watch?talk=vod_da1_s1_big_lake
- https://cloud.google.com/bigquery/docs/access-control
