
On April 8, 2020, BigQuery announced a beta release of materialized views. This commonly requested feature adds result caching to otherwise dynamic views. Here’s what you need to know.
Why use materialized views?
Materialized views run on top of a base table and cache the results. Essentially, the view will always serve the most recent version of the base table. Changes on the base table, its partitions or streamed data will force the view to re-read the updated parts (a whole table, partition or the delta). This enables far better performance when querying views and less data scanned. This offers a great upside to creating real-time reports and visualizations. And unlike with the BI engine, these views can be used with direct queries or via the API from any BigQuery supported tools such as Tableau, Looker, etc. and not just Data Studio.Example: Streaming Requests Data from a CDN
As an example, I am using a CDN log that is streamed into BigQuery, looking at the total number of requests and the average time between requests and requests received, grouped by status and the request URL. [sourcecode language="sql" title="Query that retrieves number of CDN requests"] SELECT httpRequest.status, httpRequest.requestUrl, count(*) requests, AVG(timestamp_diff(receiveTimestamp, timestamp, SECOND)) as avgTimeDiff FROM `streaming-via-cdn.streaming.requests` GROUP BY 1, 2 ORDER BY requests DESC [/sourcecode] In my case the query above processes 182MB. ![]()
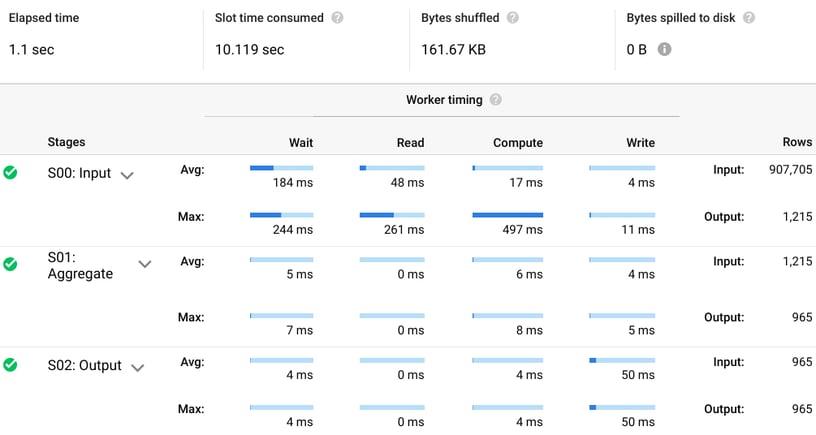 To create a materialized view, the highlighted syntax should be used before the actual query. Note that I have also removed sorting, which is not supported in materialized views. [sourcecode language="sql" title="Query that builds a materialized view" highlight="1"] CREATE MATERIALIZED VIEW `projectId.datasetId.requestsOverview` AS SELECT httpRequest.status, httpRequest.requestUrl, count(*) requests, AVG(timestamp_diff(receiveTimestamp, timestamp, SECOND)) FROM `streaming-via-cdn.streaming.requests` GROUP BY 1, 2 [/sourcecode]
To create a materialized view, the highlighted syntax should be used before the actual query. Note that I have also removed sorting, which is not supported in materialized views. [sourcecode language="sql" title="Query that builds a materialized view" highlight="1"] CREATE MATERIALIZED VIEW `projectId.datasetId.requestsOverview` AS SELECT httpRequest.status, httpRequest.requestUrl, count(*) requests, AVG(timestamp_diff(receiveTimestamp, timestamp, SECOND)) FROM `streaming-via-cdn.streaming.requests` GROUP BY 1, 2 [/sourcecode]  Now that materialized view has been created, we can query it directly as we would a regular view or a table. However, because one of the key characteristics of a materialized view is smart tuning, we can run the same query as before and our query will automatically update the execution logic to read from the materialized view's cache.
Now that materialized view has been created, we can query it directly as we would a regular view or a table. However, because one of the key characteristics of a materialized view is smart tuning, we can run the same query as before and our query will automatically update the execution logic to read from the materialized view's cache. 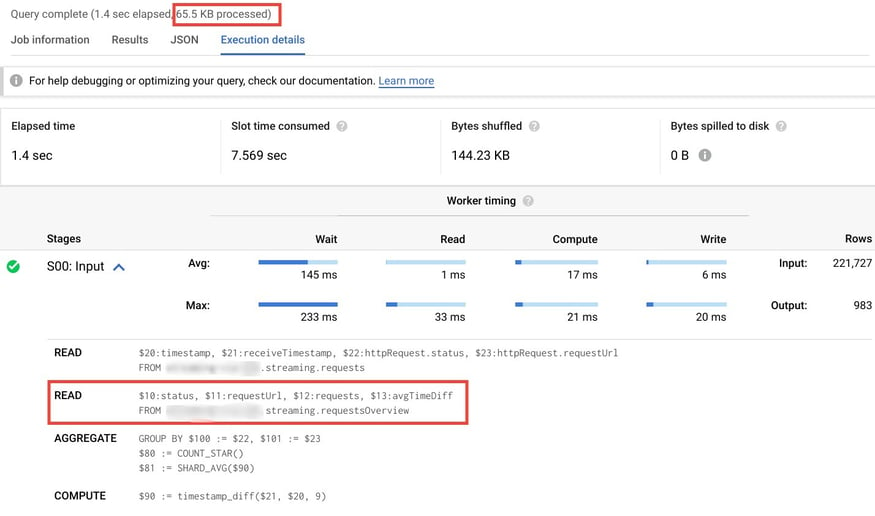 In the execution details screenshot above, you can see that running the exact same query (including sorting) utilized the existing requestsOverview materialized view to read and therefore processed far less data (65.5kB vs 182.2MB ~ 0.04%). New requests were streamed by the CDN log during my tests. Queries ran one after the other were returning up to date information.
In the execution details screenshot above, you can see that running the exact same query (including sorting) utilized the existing requestsOverview materialized view to read and therefore processed far less data (65.5kB vs 182.2MB ~ 0.04%). New requests were streamed by the CDN log during my tests. Queries ran one after the other were returning up to date information.
What is happening in the background?
You will notice that once you set up a materialized view, an automated process in the background will continue updating it. These updates are run by bigquery-adminbot@system.gserviceaccount.com.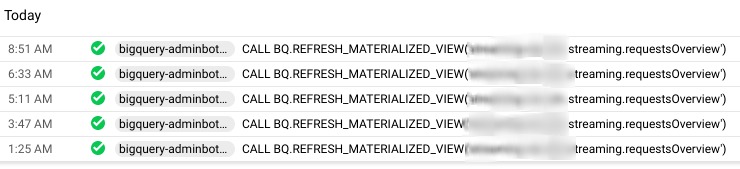 Looking at the query details, you can see that even in the background refresh, materialized views continue updating on only new or updated data, using incremental refresh. This will add a maintenance cost. The project executing this process will be charged the bytes billed amount at each refresh.
Looking at the query details, you can see that even in the background refresh, materialized views continue updating on only new or updated data, using incremental refresh. This will add a maintenance cost. The project executing this process will be charged the bytes billed amount at each refresh. 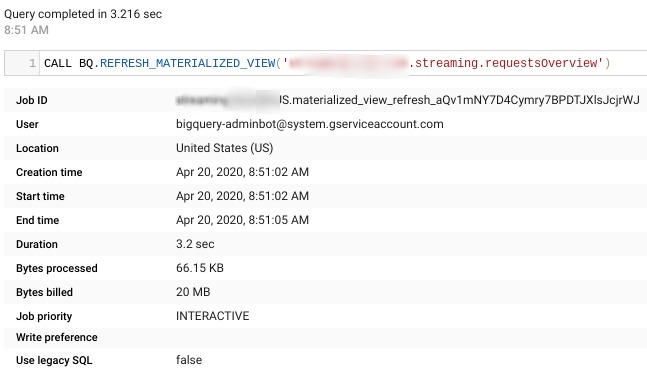 You can find refresh settings in the materialized view details. Refresh parameters can be set at materialized view creation using options.
You can find refresh settings in the materialized view details. Refresh parameters can be set at materialized view creation using options. 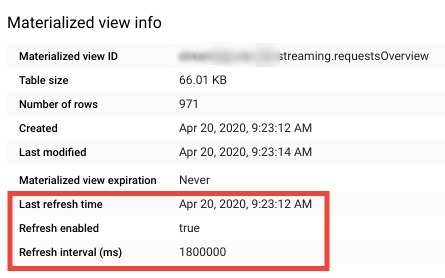
What are the limitations of materialized views?
- There are several querying limitations:
- UNNESTING is not allowed
- COUNT DISTINCT is not supported (use approx count distinct instead)
- Analytics functions are not supported
- Sorting is not supported
- Joins are not supported
- Current time functions are not supported (CURRENT_TIMESTAMP)
- Subqueries and UDFs are not supported
- All columns need to be named
- There can be a maximum of 20 materialized views per table
- It cannot reference wildcard (sharded) tables
- Materialized view has to be created in the same dataset as the table it references
