
Share



In this post, I'll walk you through a few Ads Data Hub (ADH) queries that will help you get started quickly. If you're not familiar with ADH yet, here's a quick intro to the tool.
 *Here's a paths table schema
*Here's a paths table schema
 To make things even easier, I added a flag to each of the three joining tables which ultimately allowed me to utilize countif. [sourcecode lang="sql" highlight="13" title="Campaign Overlap"] SELECT *, round(conversionsUsersWhoSawA/usersSawA*100, 2) conversionRateA, round(conversionsUsersWhoSawB/usersSawB*100, 2) conversionRateB, round(conversionsUsersWhoSawAandB/usersSawAandB*100, 2) conversionRateAandB FROM( SELECT count(campaignA.user_id) usersSawA, count(campaignB.user_id) as usersSawB, count(campaignA.user_id )+count(campaignB.user_id)-count(*) usersSawAandB, countif(campaignAFlag=1 and conversionFlag=1) as conversionsUsersWhoSawA, countif(campaignBFlag=1 and conversionFlag=1) as conversionsUsersWhoSawB, countif(campaignAFlag=1 and campaignBFlag=1 and conversionFlag=1) as conversionsUsersWhoSawAandB, FROM( SELECT DISTINCT user_id, 1 campaignAFlag FROM adh.cm_dt_impressions WHERE event.campaign_id = 37 ) as campaignA FULL OUTER JOIN (SELECT DISTINCT user_id, 1 campaignBFlag FROM adh.cm_dt_impressions WHERE event.campaign_id = 2) as campaignB using(user_id) LEFT OUTER JOIN (SELECT DISTINCT user_id, 1 conversionFlag FROM adh.cm_dt_activities) as conversion using(user_id) ) [/sourcecode] In the case of sandbox data, the conversion rate by users who saw ads from campaign A and campaign B outperforms all users who saw A or B by about 15 percent. This is a pretty common observation. An analysis like this one can give you a better perspective on the synergy of campaigns.
To make things even easier, I added a flag to each of the three joining tables which ultimately allowed me to utilize countif. [sourcecode lang="sql" highlight="13" title="Campaign Overlap"] SELECT *, round(conversionsUsersWhoSawA/usersSawA*100, 2) conversionRateA, round(conversionsUsersWhoSawB/usersSawB*100, 2) conversionRateB, round(conversionsUsersWhoSawAandB/usersSawAandB*100, 2) conversionRateAandB FROM( SELECT count(campaignA.user_id) usersSawA, count(campaignB.user_id) as usersSawB, count(campaignA.user_id )+count(campaignB.user_id)-count(*) usersSawAandB, countif(campaignAFlag=1 and conversionFlag=1) as conversionsUsersWhoSawA, countif(campaignBFlag=1 and conversionFlag=1) as conversionsUsersWhoSawB, countif(campaignAFlag=1 and campaignBFlag=1 and conversionFlag=1) as conversionsUsersWhoSawAandB, FROM( SELECT DISTINCT user_id, 1 campaignAFlag FROM adh.cm_dt_impressions WHERE event.campaign_id = 37 ) as campaignA FULL OUTER JOIN (SELECT DISTINCT user_id, 1 campaignBFlag FROM adh.cm_dt_impressions WHERE event.campaign_id = 2) as campaignB using(user_id) LEFT OUTER JOIN (SELECT DISTINCT user_id, 1 conversionFlag FROM adh.cm_dt_activities) as conversion using(user_id) ) [/sourcecode] In the case of sandbox data, the conversion rate by users who saw ads from campaign A and campaign B outperforms all users who saw A or B by about 15 percent. This is a pretty common observation. An analysis like this one can give you a better perspective on the synergy of campaigns. 
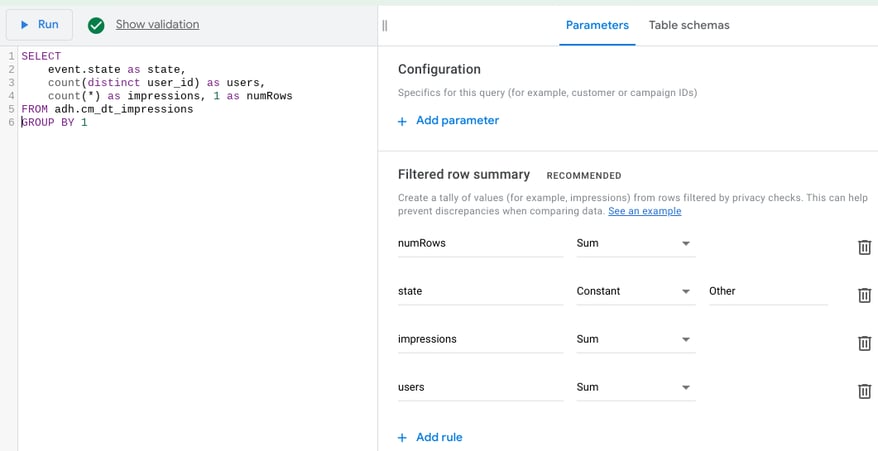 As you can see below, the results of our query showed that 27 states did not meet the minimum privacy requirements and were bucketed together accounting for 4,778 impressions.
As you can see below, the results of our query showed that 27 states did not meet the minimum privacy requirements and were bucketed together accounting for 4,778 impressions. 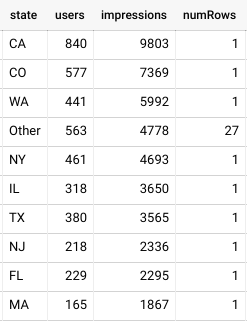 Here's a quick overview of the process that happens in the background. ADH results in red are grouped together into a "filtered" row that's then exported to BQ.
Here's a quick overview of the process that happens in the background. ADH results in red are grouped together into a "filtered" row that's then exported to BQ.  *Note that "rows" is a reserved keyword. To avoid any issues, we're using numRows as the attribute
*Note that "rows" is a reserved keyword. To avoid any issues, we're using numRows as the attribute
Attribution Modelling (with Paths)
When it comes to attribution, ADH offers two approaches. You can either use "raw" impressions, clicks, and activities tables which will require a bit more complex query, including multiple joins on a user/device identifier - or you can utilize the pre-built paths* tables that include click, view and floodlight events for each user over a 30-day window. Below is an example of a simple query that examines the most popular combination of two actions before a conversion (FLOODLIGHT event type). [sourcecode lang="sql" higligh="6" title="Event Type Combinations per User"] SELECT event_type, event_type_back1, event_type_back2, count(*) as frequency FROM( SELECT event_type, lag(event_type) OVER (PARTITION BY user_id ORDER BY event_time) event_type_back1, lag(event_type,2) OVER (PARTITION BY user_id ORDER BY event_time) event_type_back2 FROM adh.cm_paths as paths, unnest(path.events) as events) GROUP BY 1,2,3 ORDER BY 4 DESC [/sourcecode] You may notice that I'm not filtering by event_type = "FLOODLIGHT". As with other ADH queries, a good practice is to do additional filtering on the aggregated data in BigQuery (BQ) itself. In our case, filtering for event_type = "FLOODLIGHT" can be done in BQ. Having additional data also allows us to run analysis such as conversion rate per event_type combination. [sourcecode lang="sql" highlight="6" title="Examining the Results in BQ"] SELECT event_type_back1, event_type_back2, sum(frequency) frequency, sum(IF(event_type = "FLOODLIGHT", frequency, 0)) as conversions, round(sum(IF(event_type = "FLOODLIGHT", frequency, 0))/sum(frequency)*100, 2) as convRate FROM `ap-adh.full_circle_shared.pathsblog` GROUP BY 1,2 ORDER BY 3 DESC [/sourcecode] *Here's a paths table schema
Campaign Overlap
Often our clients are interested in campaign synergy, like how frequently conversions are a result of users seeing an ad from campaigns A and B, and comparing that performance to the two campaigns individually. As a part of data privacy measurements, specific logical expressions in countif, such as campaignA.user_id is not null, will result in an error. That's why we resorted to some basic Venn diagram calculations ( A∩B = A + B - AUC).
Calculating the number of rows dropped
Due to privacy restrictions, more granular rows with less than 50 users (for impressions) are "bucketed" into a filtered row summary. This query will help you identify the number of rows that did not meet the privacy requirements. We start by assigning each row a constant 1. [sourcecode lang="sql" highlight="4" title="Number of rows dropped"] SELECT event.state as state, count(distinct user_id) as users, count(*) as impressions, 1 as numRows FROM adh.cm_dt_impressions GROUP BY 1 [/sourcecode] Along with the query make sure to always set up the "Filtered row summary" settings. In this case, we're summing the numRows attribute. As you can see below, the results of our query showed that 27 states did not meet the minimum privacy requirements and were bucketed together accounting for 4,778 impressions. Here's a quick overview of the process that happens in the background. ADH results in red are grouped together into a "filtered" row that's then exported to BQ. *Note that "rows" is a reserved keyword. To avoid any issues, we're using numRows as the attribute
