
Share



Let’s face it, we all love BigQuery ML (BQML), and it keeps delivering cooler features we can work with. By its nature, BQML is designed to give you great performance without a lot of tinkering with parameters. That was certainly true when only logistic and linear regression were available, but those days are long gone and we now have neural networks and boosted trees as well – both of which have a rich set of (hyper)parameters we can tune. And yes, we can sit in front of a computer and after each train, run change some numbers here and there based on intuition to improve performance, but is there a better way?
There most certainly is, and it’s nothing new, really. Automated hyperparameter tuning has been around for a long time and is also supported in the
AI Platform
. However, the one in AI Platform is a bit of an overkill for BQML. We can make it a bit easier to set up, but equally effective.
We’ll use
Google Colab
and a python package called
Optuna
to demonstrate how to automate the tuning process. Our goal is to create a process that will run the model multiple times, each time with slightly different hyperparameters, in hopes of finding the best set.
To get started, we need a dataset to work with. We’ll go with the census data publicly available in BigQuery
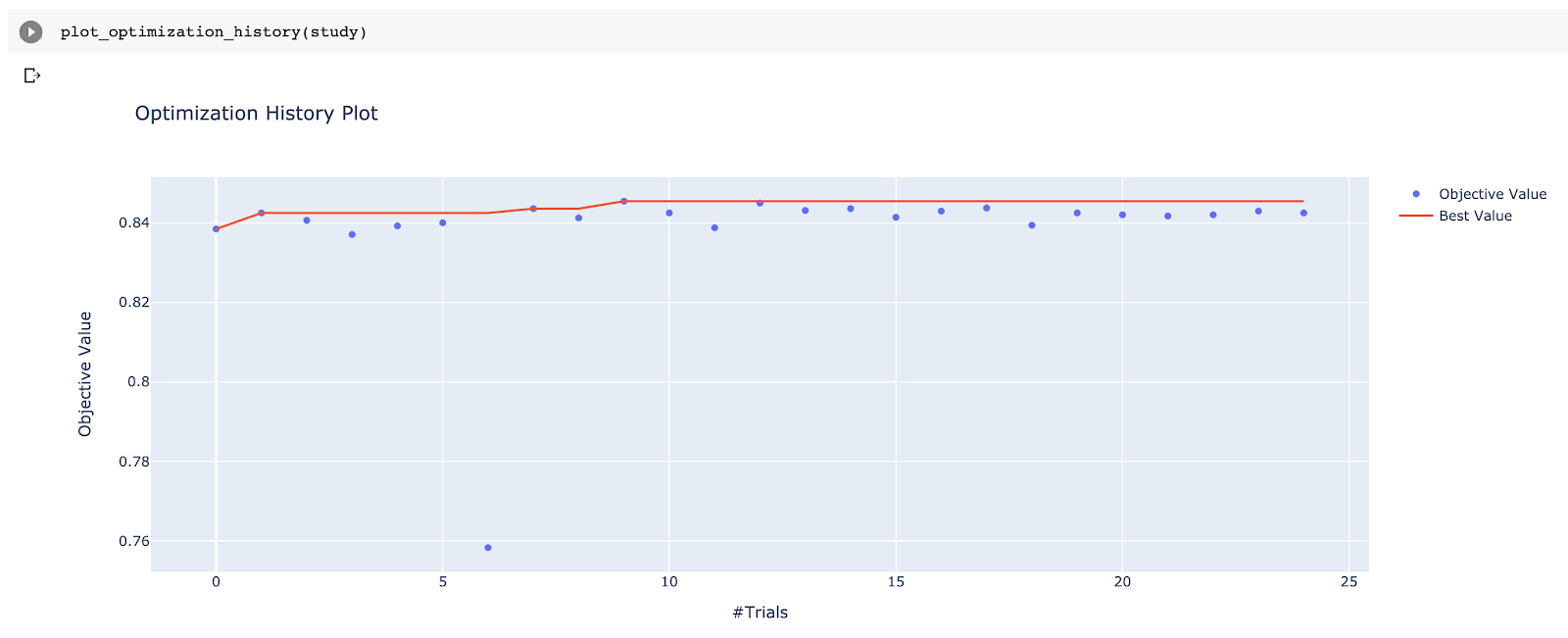
`bigquery-public-data.ml_datasets.census_adult_income`The dataset has about 32,000 rows and is a multi-label classification problem where we need to predict the income bracket. We chose accuracy as the metrics to optimize. The first thing we must do is to split the dataset into a training dataset and an evaluation dataset. It’s very important to ensure all our runs evaluate exactly the same dataset. Make sure no row ends up in both training and evaluation datasets. Once we have the datasets ready, we have to write some python code to handle BQML: [sourcecode language="python"]&lt;/pre&gt; import uuid from google.cloud import bigquery class BQMLLogRegModel(object): def __init__(self, project_id, **kwargs): self.bq = bigquery.Client(project=project_id) self.model_name = str(uuid.uuid1()).replace('-', '') def fit(self, table, **kwargs): create_model_job = self.bq.query(''' CREATE OR REPLACE MODEL `demo.{model_name}` OPTIONS( MODEL_TYPE='LOGISTIC_REG', L2_REG={L2_REG}, LS_INIT_LEARN_RATE={LS_INIT_LEARN_RATE}, MIN_REL_PROGRESS={MIN_REL_PROGRESS} ) AS SELECT * EXCEPT(income_bracket), income_bracket as label FROM `demo.{table}` '''.format( model_name=self.model_name, table=table, **kwargs )) # wait till done create_model_job.result() def eval(self, table, **kwargs): df_eval = self.bq.query(''' SELECT * FROM ML.EVALUATE(MODEL `demo.{model_name}`, ( SELECT *, income_bracket as label FROM `demo.{table}` ) ) '''.format( model_name=self.model_name, table=table, **kwargs )).to_dataframe() return df_eval.iloc[0]["accuracy"] def delete(self): self.bq.delete_model("demo.{}".format(self.model_name)) &lt;pre&gt;[/sourcecode] We have three functions written: fit, eval, and delete. The fit function actually runs the CREATE MODEL statement and also has three parameters that can be openly defined (L2_REG, LS_INIT_LEARN_RATE, MIN_REL_PROGRESS). The val function calls ML.EVALUATE and extracts the accuracy of the model, which will be used as the metric being optimized. And the delete function just deletes the model after the run is finished. The next piece of code already does what we want as our end goal: [sourcecode language="python"]</pre> import optuna # Step 1: Define an objective function to be maximized. def objective(trial): # Step 2: Define trial parameters L2_REG = trial.suggest_uniform('L2_REG', 0.0, 1.0) LS_INIT_LEARN_RATE = trial.suggest_loguniform("LS_INIT_LEARN_RATE", 0.0001, 1) MIN_REL_PROGRESS = trial.suggest_loguniform("MIN_REL_PROGRESS", 0.000001, 0.1) model = BQMLLogRegModel('<project-id>') model.fit('census_train', L2_REG=L2_REG, LS_INIT_LEARN_RATE=LS_INIT_LEARN_RATE, MIN_REL_PROGRESS=MIN_REL_PROGRESS) # Step 3: Scoring method accuracy = model.eval('census_eval') model.delete() return accuracy # Step 4: Running it study = optuna.create_study(direction="maximize") study.optimize(objective, n_trials=25) <pre>[/sourcecode] Optuna requires you to define one function that represents one training run and does the rest for you. You just need to ensure what you’re returning from the function is the metric you want to optimize (either maximize or minimize). Once you start running this code, the automated hyperparameter tuning begins and you just need to wait for it to finish. Of course, the information about all run metrics, such as the objective value (accuracy), time to run, and trial number, are all easily available after, along with some great built-in visualizations.
In our case, all runs were pretty close but the best set of parameters were: L2_REG: 0.7208160880000997 LS_INIT_LEARN_RATE: 0.12645904720835036 MIN_REL_PROGRESS: 0.00020628985519325206Once your model is tuned, you have a world of possibilities open to you, but the first step would be to run the prediction in an automated way. Need help? Check out this blog post that covers BQML model automation. And if you have any questions, please feel free to contact us !
