
Ready to Flex Your BigQuery Muscles?
Welcome to Adswerve's 31 Days of BigQuery, where each day in May brings a new mini challenge to sharpen your skills, stretch your brain, and maybe even spark a little friendly competition. Whether you’re a BigQuery beginner or a seasoned SQL wizard, there’s something here for you.
These challenges were thoughtfully crafted (and solved!) by Adswerve’s Technical Services team—the behind-the-scenes problem solvers who build, architect and scale data solutions for our clients every day. Now, we're sharing that expertise with you.
Each day in May, we will post a new 10-minute BigQuery challenge for you to solve, with the solution provided the following day. The challenges will cover a wide variety of BigQuery features and will become more difficult as the month progresses. Feel free to reach out via our social channels with any questions.
As with many data problems, most of the challenges may have more than one solution; we would be excited to hear if your solution differs from ours.
Day 1 - Create your own BigQuery Instance
Challenge:
For this first challenge, set up your own Google Cloud project, enable BigQuery, and query the public dataset. BigQuery is available in a free "sandbox" environment, limiting you to 10GB of storage and 1TB of monthly queries.
When ready, use standard SQL in the BigQuery studio to retrieve the top 5 most popular names in the US during the years 2010 and 2019 using the publicly available table `bigquery-public-data.usa_names.usa_1910_current`.
Tip
BigQuery comes with a large amount of publicly available data. I encourage you to explore these datasets; many have come in handy in the past.
Resources
https://cloud.google.com/bigquery/public-data
https://cloud.google.com/bigquery/docs/sandbox
https://console.cloud.google.com/marketplace/product/social-security-administration/us-names
https://www.w3schools.com/sql/
Solution
The 5 most popular names in the US during the period of 2010 to 2019 are Emma, Olivia, Noah, Sophia and Liam.
A possible SQL approach:
#1 Challenge
SELECT name, sum(number) as number
FROM `bigquery-public-data.usa_names.usa_1910_current`
WHERE year BETWEEN 2010 and 2019
GROUP BY 1
ORDER BY 2 DESC
LIMIT 5
Day 2 - Quickly Chart Query Outputs
On day two, we will explore an underutilized (personal opinion) feature hidden in the query output. While BigQuery allows you to open your query results in Looker Studio, Python notebooks, and data canvas, sometimes the quickest way to visualize is only a couple of clicks away in the "Chart" tab.
Challenge
In this challenge, build a chart using the public dataset (`bigquery-public-data.usa_names.usa_1910_current` ) from the first challenge that visualizes the popularity of your name and a few other names throughout the years. See the screenshot below as an example of the expected output.
Tip
You will notice that while the Chart function is easy to use, it comes with limitations, such as only allowing a single dimension, but allowing up to 5 measures.

Solution
Because the built-in charting solution only allows a single dimension and multiple measures, I added each of the observed names as a sum(if metric. Make sure to order by year for the visualization to be rendered as expected.
#2 Challenge
SELECT
year,
sum(if(name = "Luka", number, 0)) as Luka ,
sum(if(name = "Peter", number, 0)) as Peter,
sum(if(name = "Luca", number, 0)) as Luca ,
FROM `bigquery-public-data.usa_names.usa_1910_current`
GROUP BY ALL
ORDER BY year ASC
Day 3 - Query Costs
Understanding query costs is crucial for managing your overall #BigQuery expenses. While the primary BQ charges are for storage and analysis (querying), advanced features like streaming inserts, BI Engine, Storage API, Notebook Runtimes, and BigQuery reservations can also contribute to costs as your usage evolves.
Challenge
Estimate the cost of the queries you wrote on days 1 and 2. In the on-demand pricing mode (most common), the cost is determined by the amount of data scanned for a query. Queries written in the UI (if valid) provide an estimate of how much data will be scanned in the query validator below the input window (see the screenshot).
Queries are charged at $6.25 per TiB or $0.00625 per GiB scanned.
Explore more
See how the price of queries changes with more or fewer columns selected, see what happens when using filters and limits. Think about how BigQuery’s columnar storage impacts the price of these queries.
Resources:
https://cloud.google.com/bigquery/docs/storage_overview
https://cloud.google.com/bigquery/pricing

Solution
The queries used in the previous challenges are both 143.71MB in size, which translates to 143.71MB => 0.00014371TB
0.00014371TB x $6.25/TB = $0.0008981875
Adding more columns increases the size of the queries, while using limit and filters does not impact the cost of the query due to BigQuery scanning each column fully.
Day 4 - Table Date Sharding
BigQuery supports table sharding as a way to divide your data, often seen with daily exports like Google Analytics 4 (events_YYYYMMDD). While you can query these daily tables individually, BigQuery lets you query them collectively using a wildcard (*) combined with the _TABLE_SUFFIX pseudo-column to filter specific date ranges.
Challenge
Using the public Google Analytics 4 dataset sample available at:
bigquery-public-data.ga4_obfuscated_sample_ecommerce run a query that provides the number of sessions (session_start events) between December 1 and December 31 2020.
Explore more
Keep in mind that while sharding is common in some exports, partitioning is generally the recommended approach in BigQuery for benefits like performance and easier management. We'll explore partitioning soon!
Resources
https://lnkd.in/d6tc5p8G
https://lnkd.in/daftABea
Solution
#4 Challenge
SELECT
COUNTIF(event_name = "session_start") as sessions
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
WHERE
_table_suffix BETWEEN "20201201" AND "20211231"
Day 5 - Repeated Fields
The use of repeated fields in BigQuery is one of the biggest differences when comparing BQ to traditional (relational) SQL databases such as MySQL, PostgreSQL, etc. The array field in BigQuery not only introduces a new way to store data, but also challenges the need to normalize tables.
For example, a table of customers with their phone numbers, where each customer can have multiple phone numbers, would require two separate tables in a traditional database (per first normal form), whereas in BigQuery, customers' phone numbers can be stored in an Array (repeated) field for each customer.
In the previous challenge, we explored the Google Analytics 4 sharded tables. The events table stores event parameters as an Array (repeated field) of structs (container of multiple fields). In practice, each Google Analytics event has multiple event parameters. An array of structs is almost like a table within each row (event) and can be queried as a parameter.
Challenge
Complete the following query to produce an output of pageviews per page location for January 31, 2021 of the Google Analytics 4 sample table.
#4 Challenge
SELECT
(SELECT _________ FROM unnest(__________) WHERE key = "page_location") as page_location,
countif(event_name = “page_view”) as page_views
FROM
bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131
GROUP BY page_location
Explore more
The event table has multiple repeated fields. Can you find them all? Why was an array used to represent those fields?
Resources
Work with arrays - https://lnkd.in/d9EWUi6K
Google Analytics 4 export schema - https://lnkd.in/d_r7dQGw
Solution
We were looking for value.string_value and event_params to fill the blanks. In the Google Analytics export's event parameters, values can come as different data types, that's why inside the value struct we specifically reference string_value.
SELECT
(SELECT value.string_value FROM unnest(event_params) WHERE key = "page_location") as page_location,
countif(event_name = “page_view”) as page_views
FROM
bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131
GROUP BY page_location
Day 6 - Window Functions & CTEs
On day 5 we looked at how repeated fields (Arrays) work in BigQuery. Today, let's tackle Window Functions and Common Table Expressions (CTEs).
- Window Functions: perform calculations across a set of rows that are somehow related. Unlike aggregate functions such as SUM, COUNT, AVG, etc. they do not collapse the rows. Instead, they return a value for each row based on a “window” they are in. Today, we’ll use them to create a new dimension for the Google Analytics 4 sample that will number events in a session.
- CTEs or Common Table Expressions defined using the WITH clause allow you to create a temporary, named query that can be referenced within the same query as any other table. This is incredibly useful to break down complex queries into more manageable and readable parts.
Challenge
Use a CTE to define a base query. The base query should include event_timestamp, event_name, geo.region, device.web_info.browser, user_pseudo_id (unique user identifier) and ga_session_number (an integer value from event_param repeated field with the key ga_session_number. The GA Session Number indicates the number of sessions a user has had on your website or app (a counter that increases with each visit).
For each session number, the events in each session (starting with 1 for the first event in the session) are ordered by the event_timestamp.
If you’re new to window functions, the resources below has great examples to get you started.
Tip
Resources
Window Functions in BigQuery - https://cloud.google.com/bigquery/docs/reference/standard-sql/window-function-calls
Solution
WITH base AS (
SELECT
event_timestamp,
geo.region,
device.web_info.browser,
event_name,
user_pseudo_id,
(SELECT value.int_value FROM unnest(event_params) WHERE key = "ga_session_number") as ga_session_number
FROM `bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
)
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY user_pseudo_id, ga_session_number ORDER BY event_timestamp) as hit_number
FROM base
Day 7 - Data Definition Language
Data definition language (DDL) allows you to create, delete, and alter resources in BigQuery. Think of DDL as part of SQL that provides a way to define and manage the structural aspects of your data warehouse (BigQuery). In BigQuery, many resources can be controlled through the UI, however, knowing how to build and manage resources using DDL will help you get quicker and allow you to automate some of these processes.
Challenge
Create a dataset (schema) and a table using DDL. Create your table in the newly created dataset on top of the query from the previous challenge using the AS keyword in the create table SQL.
Tips
You will have to use the following two DDL commands:
- CREATE SCHEMA
- CREATE TABLE AS SELECT
Resources
https://cloud.google.com/bigquery/docs/reference/standard-sql/data-definition-language
Solution
#Create a dataset:
CREATE SCHEMA bqchallenges;
#Create a table based on a query
CREATE TABLE
bqchallenges.ga_data
AS
WITH base AS (
SELECT
event_timestamp,
geo.region,
device.web_info.browser,
event_name,
user_pseudo_id,
(SELECT value.int_value FROM unnest(event_params) WHERE key = "ga_session_number") as ga_session_number
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
)
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY user_pseudo_id, ga_session_number ORDER BY event_timestamp) as hit_number
FROM base;
Day 8 - Optimize with Partitioning & Clustering
On Day 3, we saw how query costs relate to the amount of data scanned in your query. Today, let's se optimize those costs and boost speed using partitioning and clustering!
Partitioning
Think of a partitioned table as a well-organized filing cabinet. Instead of one giant drawer, your table is divided into smaller, more manageable segments (partitions) based on the values in a specific partition column. When you query data and filter by the partition column (a date range), BigQuery can skip scanning irrelevant partitions entirely, leading to faster queries and lower costs.
In BigQuery, the partition column can be an integer, a time-unit, or the ingestion time. A table can have up to 10,000 partitions.
Clustering
If partitioning is like having separate drawers, clustering is like having alphabetically sorted files within those drawers. BigQuery sorts the data within storage blocks based on the values in one or more clustering columns. When you filter or aggregate on these columns, BigQuery can more efficiently locate the relevant blocks and rows. This is especially beneficial for columns with high cardinality that you frequently filter on.
In BigQuery you can specify up to four clustering columns. Unlike partitioning, there's no limit to the number of unique values in clustering columns. Take advantage of both for optimal performance!
Challenge
Create a partitioned and clustered table, by slightly rewriting yesterday’s solution below to include all the events_ tables using the wildcard notation. Then transform the table suffix to a date type using parse_date(“%Y%m%d”, _table_suffix) as table_date so it can be used as a partition. Use event name, browser and region as clustering columns
Explore More
See how using filtering by these columns when querying the newly created table changes the amount of data scanned. How does scanned data prediction compare between partitioning and clustering?
Resources
Partitioning - https://lnkd.in/gNRQwsFm
Clustering - https://lnkd.in/dhsjYDZp
Solution
CREATE TABLE bqchallenges.ga_data_par_clu
PARTITION BY table_date
CLUSTER BY event_name, browser, region
AS
WITH base AS (
SELECT
parse_date("%Y%m%d", _table_suffix) as table_date,
event_timestamp,
geo.region,
device.web_info.browser,
event_name,
user_pseudo_id,
(SELECT value.int_value FROM unnest(event_params) WHERE key = "ga_session_number") as ga_session_number
FROM `bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
)
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY user_pseudo_id, ga_session_number ORDER BY event_timestamp) as hit_number
FROM base
Day 9 - Setting up hard limits
Despite careful query cost management and adherence to best practices, unexpected spikes can still occur. To prevent runaway costs,BigQuery provides hard limits on the daily data scanned at both project and project-user levels.
Challenge
Today's challenge is simple. In the Quotas & System Limits section of your GCP project, set a daily query usage limit.
Solution
- Open your GCP project
- Navigate to Quotas and System Limits

- Filter for query usage

- Check the quota you'd like to implement (per day or per user per day) and click edit
- Update the value (uncheck unlimited) and click submit request

Day 10 - Unleash the Power of External Tables with BigQuery!

BigQuery offers a fantastic way to seamlessly integrate with external data sources, like Google Sheets. This is a very effective way of collaborating with teams who prefer managing data outside of BigQuery and SQL, but want to see the impact of their changes immediately.
Challenge
In this challenge, set up an external Google Sheets table by following the documentation https://cloud.google.com/bigquery/docs/external-data-drive and join it with a public dataset.
An example would be providing a margin for each item category in a Google Sheets document and then joining that data with the public GA4 data to calculate profit, and not just the revenue of items sold (screenshot below).
Explore More
Test the live connection, check how changes in the document immediately impact the outputs of your queries.
Solution
Follow the provided documentation to create a new external table. Any query combining the newly create table and a public dataset works, the screenshot above is an example of a combination of financial Google Doc and the GA4 sample dataset.
Day 11 - The Information Schema
The BigQuery Information Schema provides invaluable insights into the metadata and execution history of your BigQuery resources. By querying these system-defined views, you can gain detailed information about your datasets, tables, job execution, and more.
Challenge
Review queries you ran in your project in May so far and sort them from the most to the least expensive.
- You'll primarily need to query the INFORMATION_SCHEMA.JOBS_BY_PROJECT view.
- Look for the total_bytes_billed column to determine query cost
- The query column contains the actual SQL text of the executed job
- The creation_time column can be used to filter to May
Resources
Information Schema Views - https://lnkd.in/dDfpXhca
Information Schema Jobs - https://lnkd.in/dExxvrFP
All about information schema and BigQuery processing cost
SELECT
user_email,
query,
total_bytes_billed
FROM
`region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
creation_time BETWEEN "2025-05-01"
AND "2025-05-31"
AND job_type = "QUERY"
ORDER BY
total_bytes_billed DESC
LIMIT
10
Day 12 - Storage Billing Model
Another underutilized, and possibly massively beneficial feature in BigQuery is the ability to decide how a dataset will be charged for storage. The standard rate is $0.02 per GB per month for the first 90 days, which drops to $0.01 per GB per month when the data is older than that. The above pricing applies to the more commonly used logical storage-based billing. However, BigQuery allows you to be billed at double the rate per Physical (compressed) + time travel bytes.
For analytical and denormalized tables, physical storage can be significantly smaller (often 10-20x!), potentially leading to 5-10x storage cost reductions. As an example, the table in the second screenshot is using 21.94GB of logical storage (uncompressed) but only 1.13GB physical – that's a massive 90% potential saving!
Table id: bigquery-public-data.samples.natality
Dataset storage billing can be changed at any point and does not impact the query execution.
The query in the screenshot below is one of the most magical pieces of the BigQuery documentation available. Hidden in the information schema table storage documentation (https://lnkd.in/d3D_TMJc) it examines your datasets and determines which billing model is better for your datasets and what the savings are.
Challenge
Execute the query from the documentation in your GCP project and update the datasets that would benefit from switching the billing model using the query below:
ALTER SCHEMA DATASET_NAME
SET OPTIONS( storage_billing_model = 'BILLING_MODEL');
Day 13 - GEO
BigQuery supports the geography data type, enabling you to work with spatial information directly within your data warehouse. This means you can store geographic points, lines, and polygons and apply specialized functions to them. These functions allow you to perform complex spatial operations, such as calculating distances and areas, checking for intersections, and determining containment.
For this example, we'll look into the public dataset "geo_us_boundaries" to test some of the geography functions on the polygons of different zip codes.
Challenge x 2
Start querying the bigquery-public-data.geo_us_boundaries.zip_codes table to solve the following two challenges:
- Using the st_area function on the ZIP code area field (zip_code_geom), order zip codes from largest to smallest, what are the top 3 biggest zip codes*?
- Find the zip code farthest away from Times Square
ST_GEOGPOINT(-73.985130, 40.758896)*The area function returns square meters
Resources
GEO functions: https://lnkd.in/gryAGF2T
Zip Code public data: https://lnkd.in/gX55fEsd
Solution
SELECT
*
FROM `bigquery-public-data.geo_us_boundaries.zip_codes`
ORDER BY st_area(zip_code_geom)
DESC LIMIT 5;
SELECT
zip_code,
st_distance(ST_GEOGPOINT(-73.985130, 40.758896), zip_code_geom) as distance
FROM `bigquery-public-data.geo_us_boundaries.zip_codes`
ORDER BY distance DESC;
The zip code farthest from Times Square in NYC is 96916.
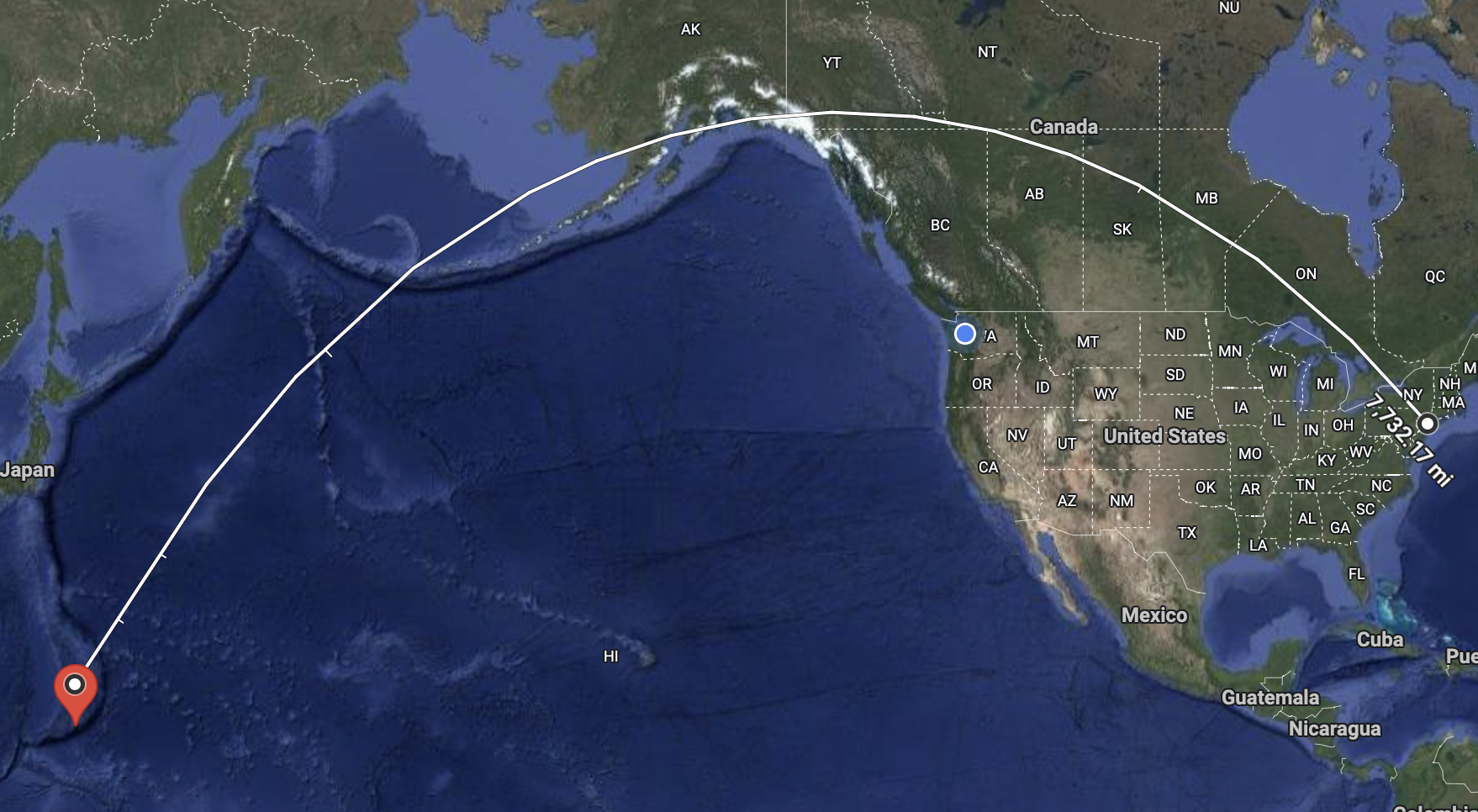
Day 14 - Time Travel
BigQuery has a built-in "time machine" that allows you to access a snapshot of your table from any point within its time travel window (default is 7 days). This means you can easily recover from accidental or intentional data changes by simply specifying a past timestamp!
How it works in SQL:
Just append FOR SYSTEM_TIME AS OF followed by a timestamp to your table reference.
To reference a table state from 5h ago:
`my_dataset.my_table` FOR SYSTEM_TIME AS OF TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 5 HOUR);
To start this challenge, first create a sample table in your project. Such as copying the Google Analytics 4 public table:
CREATE OR REPLACE TABLE `bqchallenges.my_time_travel_table`
AS
SELECT * FROM `bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`;
After creating the table, note down the Unix milliseconds value, this is the time we will be travelling back to.
SELECT unix_millis(current_timestamp());
Now, "accidentally" delete all the page views from the table:
DELETE FROM `adswerve-ts.bqchallenges.my_time_travel_table`
WHERE event_name = "page_view";
Challenge
1. Verify the change: Write a query using FOR SYSTEM_TIME AS OF TIMESTAMP_MILLIS([your_recorded_unix_millis_value]) to compare the row count of the table at its creation time with its current state.
2. Restore the past: Write a query to retrieve the table data as it was before the deletion.
Tip
- Remember this powerful feature! You can be a data hero by recovering accidentally modified or deleted data.
- For extreme emergencies, BQ Tables also have a lesser-known fail-safe window, which allows tables to be restored up to 7 days after deletion.
Resources
System time as of: https://lnkd.in/d6yVbtGp
Access historical data: https://lnkd.in/d9xaj2dj
Fail safe: https://lnkd.in/ga_aDZRu
Day 15 - User-Defined Functions
BigQuery's User Defined Functions (UDFs) allow you to create functions in JavaScript, SQL, or now even in Python (preview). These functions can be temporary or persistent. Today, we'll look into temporary functions that expire as soon as your query is finished executing, and tomorrow we'll focus on permanent (stored) functions.
UDF functions are useful to store and reuse frequently used logic, simplify complex queries, and overall improve readability. In BigQuery, they also allow you to use outside libraries and non-SQL languages. A UDF executes on each row and can take multiple column values as its arguments.
Example
CREATE TEMP FUNCTION sum_three_numbers(x INT64, y INT64, z INT64)
RETURNS INT64
AS (
x + y + z
);
SELECT sum_three_numbers(x, y, z) FROM numbers
Challenge
Using the solution from the GEO challenge on day 13 create a temporary function that translates the distances from meters to miles.
Day 16 - User-Defined Functions in Python
Python UDFs in BigQuery enable you to transform your data using Python and Python packages directly in your SQL queries. In the screenshot below, you can see a snippet from the documentation (linked in the resources) creating a permanent function that imports scipy to calculate the area of a circle given the radius.
This function could then be easily called in a SQL querying a table of radii:
SELECT dataset.area(radius) FROM table_of_circle_data
Challenge
Create a permanent Python function that uses a PyPI package. You can tackle yesterday's problem using the unit-convert project (https://lnkd.in/dr4_wJKY).
Resources
https://lnkd.in/dBQKCCVh
Day 17 - Creating a Training Table for BQML
Over the next couple of days, we will build a simple machine learning model within BigQuery and run predictions. First, we will build a training table that includes existing and engineered features that predict an outcome.
For this case, I will be using BigQuery's public data natality table (bigquery-public-data.samples.natality). The goal of the model will be to predict newborns' weight based on the information given to us at the time of birth.
A good training table includes a target variable (in our case weight_pounds) on the rightmost side of the table and features that will be used to predict that variable on the left. Explore the features in the table and find some that already have a good correlation with the outcome.
Challenge
Using DDL (Challenge Day 7), create a training table using the natality table. Keep it clean and simple, using only a few features, see if potential features have any outliers that need to be handled, how they're correlated to the outcome already and make sure that there is no Data Leakage.
More
BigQuery comes with a set of functions meant for feature engineering such as BUCKETIZE, SCALER, NORMALIZER... See what they can do and feel free to include them in your training table.
https://lnkd.in/dDe5TQ3c
Solution
I translate the weight in pounds to kilograms and rename the target column to label (which is expected by the BQML create model). I ran a few quick tests and saw that selected features impact the average weight.
In the process, I noticed that father_age uses the value 99 for unavailable data. I will implement that as a part of the model transformation process, and not in the training table.
CREATE OR REPLACE TABLE mydataset.my_train_table
AS
SELECT
is_male,
plurality,
cigarette_use,
alcohol_use,
mother_age,
state,
father_age,
weight_pounds*0.45359237 as label
FROM
`bigquery-public-data.samples.natality`
Day 18 - Create a BQML Model
In yesterday's challenge, we created a training table to train a BQML model. Today, we'll use the create model function to build a model. The CREATE MODEL statement in BigQuery ML allows you to build machine learning models directly within BigQuery using SQL. This eliminates the need to export data or use separate machine learning tools. By specifying the model type and training data in your SQL query, you can efficiently create and train models for various predictive tasks.
Use day 17 solution to build on.
Challenge
Run a create model (https://lnkd.in/dKXmA3Fu) command using a regression model, such as linear regression, boosted tree regressor, or one of the other models available in the documentation.
Also, take advantage of the TRANSFORM function, which allows you to implement feature transformations (like handling the father's age) into the model.
Make sure to only use rows where weight_pounds is not null.
Resources
https://lnkd.in/dKXmA3Fu
Solution
CREATE OR REPLACE MODEL `bqchallenges.mymodel`
TRANSFORM(is_male, plurality, cigarette_use, alcohol_use, mother_age, state, IF(father_age = 99, Null, father_age) as father_age, label)
OPTIONS(model_type='BOOSTED_TREE_REGRESSOR')
AS
WITH train_table AS (SELECT
is_male,
plurality,
cigarette_use,
alcohol_use,
mother_age,
state,
father_age,
weight_pounds*0.45359237 as label
FROM
`bigquery-public-data.samples.natality`
WHERE weight_pounds is not null)
SELECT * FROM train_table
Day 19 - Run Predictions
With the BQML model from Day 18 in place, it's time to run predictions. We will predict a few random rows and compare these predictions to our the actual outcomes. If your model has already been created, review the evaluation tab to get a sense of its performance. In the natality model (solution from day 18 below), the average absolute error is 0.4277kg.
Challenge
Using ML.PREDICT predict the outcome (weight) for a decent amount of samples (1000) and compare the mean absolute error (MAE) between predicted labels and the actuals against the MAE of predicted labels and the average of the whole training set (3.31695kg).
The average weight of the whole dataset should serve as a good benchmark to try to beat.
Tip
See the screenshot to get you started.

Solution
SELECT
AVG(ABS(predicted_label-actual_outcome)) MAE_Model,
AVG(ABS(actual_outcome-3.3169476413297416)) MAE_AVG
FROM (
SELECT
*
FROM
ML.PREDICT(MODEL `adswerve-ts.bqchallenges.mymodel`,
(
SELECT
is_male,
plurality,
cigarette_use,
alcohol_use,
mother_age,
state,
father_age,
weight_pounds*0.45359237 AS actual_outcome
FROM
`bigquery-public-data.samples.natality`
WHERE
weight_pounds IS NOT NULL
AND RAND() < 0.01 ) ) )
Day 20 - Random Sample
In BigQuery, querying a sample of data that includes all the columns can be expensive. We looked at how to solve this with partitioning and clustering when creating a new table.
However, in the most recent challenge, I suggested grabbing a sample of rows from a public dataset to run a prediction against.
On day 19 the task involved grabbing a sample of rows from a public dataset for prediction purposes. A common approach to randomly select approximately 1% of rows involves using a WHERE clause with the RAND() function:
WHERE RAND() < 0.01However, BigQuery offers a more cost-effective and (personal opinion again) underutilized clause specifically designed for random data subset selection from large tables, minimizing the amount of data scanned.
Challenge
Read about and use TABLESAMPLE to select ~5% of the data from a large public dataset such as StackOverflow questions (bigquery-public-data.stackoverflow.posts_questions) or the natality dataset that we've used in previous challenges.
Compare the cost of a query between using rand()<0.05 and TABLESAMPLE.
More info
Table sampling works by randomly selecting a percentage of BigQuery table's data blocks; the smaller the table the fewer of these blocks there are. Don't expect your percent of data requested to exactly match the same share of rows.
Resources
Table Sampling
Day 21 - AI.GENERATE
AI.GENERATE enables you to analyze a combination of text and unstructured data by sending your requests to Vertex AI Gemini model of your choice directly from BigQuery. This allows you to enrich the results of queries on your existing data.
Challenge
In this challenge feel free to use the query provided below to execute an AI.GENERATE function (or come up with your own use case). The output of it is an outdoor activity suggestion for the first time visitors to your website via the Google Analytics 4 data. Because the data provides us a location and a cookie of the user, we can use the output to potentially personalize the website for each user.
Even though the query is provided, you will still have to set up an external connection to the Vertex AI service and work with IAM to provide access to the service account communicating with the models (tutorial is available in the resources section).
WITH
user_location AS (
SELECT
user_pseudo_id,
event_date,
geo.city || ", " || geo.region AS location
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
WHERE
event_name ="first_visit"
LIMIT
10)
SELECT
user_pseudo_id,
location,
AI.GENERATE( FORMAT('Provide an outdoor activity to do on %s in %s.', event_date, location ),
connection_id => 'us.vertex_ai_remote',
endpoint => 'gemini-2.0-flash').result
FROM
user_location
AI Generate syntax
Tutorial
The Cost of using AI.GENERATE
When using the AI.GENERATE you first pay the BigQuery analysis as usual, along with that each AI request is charged.
In this case, for Gemini 2.0 flash, I calculated that the cost would be about $0.15 per 1000 rows requested.
Based on the average, roughly being:
- 100 character input
- 1,000 character output
https://cloud.google.com/vertex-ai/generative-ai/pricing

Day 22 - Monitoring
In one of the previous challenges, we examined the jobs information schema, which provides a historical record of all executed queries, including user details, bytes scanned, and the query text itself. While the information schema is invaluable for historical analysis of query performance within your project, real-time monitoring and alerting are essential for staying informed about current metrics and proactively addressing potential issues.
Challenge
Navigate to Monitoring in your Google Cloud Platform.
1. Review the available pre-built BigQuery dashboards. Run queries within your project to observe how metrics are populated and displayed in real-time.
2. Create an alerting policy to send an email notification if BigQuery scans more than 10GB of data within a 10-minute window. Trigger this alert to see it in action with a SELECT * on a public dataset such as `bigquery-public-data.samples.natality` (22GB)
Resources
Create an alert in UI - https://cloud.google.com/monitoring/alerts/using-alerting-ui
Day 23 - Query Scheduling
So far, all the queries that we've written and executed in hashtagBigQuery have been interactive, ad hoc queries in the UI. BigQuery allows you to set up ongoing queries that run in the background. The easiest way to set up an ongoing query is via the scheduled query feature.
Challenge
The Google Trends public dataset in BigQuery provides a daily overview of top trending and rising search terms internationally and in the US.
bigquery-public-data.google_trends.international_top_rising_terms
Schedule a query that selects the most recent week and refresh_date from the top_rising_terms for a region of your interest. Append the filtered down rows to a region overview table.
Resources
Scheduling Queries
Day 24 - Notebooks
BigQuery has truly evolved beyond its roots as a powerful data warehouse. In a significant leap forward over the past year, Google Cloud has integrated Python Notebooks directly into the BigQuery environment, transforming it into a holistic platform for data analysis, machine learning, and interactive exploration. This integration dramatically streamlines the data-to-insights journey, bringing the power of Python's rich ecosystem directly to your massive BigQuery datasets.
Challenge
Open a new notebook in BigQuery hand use the provided template, walk through the notebook and review how BigQuery is called (%%). Relating to yesterday's challenge also review scheduling a notebook execution.
Resources
Notebooks in BigQuery - https://lnkd.in/dxXP5BGH
Schedule Notebooks - https://lnkd.in/dHNFT6_s

Day 25 - Table creation driven processes
A couple of days ago we looked at scheduled queries, and how it's possible to set a fixed time to run your queries in the background. Since BigQuery is a part of the GCP all of it's logs end up in cloud logging. Using log explorer you can find your BigQuery interactions and create log router, which can then trigger a process (for example) via a Pub/Sub topic.
Challenge
1. Run a CREATE TABLE or a similar query in your BigQuery environment.
Example:
CREATE OR REPLACE TABLE reporting.google_trends_most_recent_Seattle
AS
SELECT * FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(current_date(), interval 1 day)
AND dma_name = "Seattle-Tacoma WA"
2. Find the table creation log in your Cloud Logging.
3. Filter on a specific logging field such as createDisposition and destinationTable and test your filter (by running query from #1 multiple times).
4. Create a sink that publishes a Pub/Sub message or uses one of the other destination options. (Actions --> Create Sink)
5. Check to see if messages are published to a Pub/Sub topic when new tables are created, if you selected a different destination such as Cloud Storage or BigQuery see if files/tables have been updated.
This is a step outside BigQuery and for the purposes of these BQ centered challenges I want to demonstrate how all queries and BigQuery actions end up in logging from where event driven actions can be triggered to start other processes.
This method is often used with the Google Analytics 4 daily data export, where time of a daily table can be a bit of a mystery.

Day 26 - Data Transfer Service
The BigQuery data transfer service is an incredibly useful feature that allows you to configure scheduled data transfers from a multitude of different sources into BigQuery.
Many of these transfers are available as free native connectors, making it easy to integrate data from popular platforms. These include Salesforce, Facebook Ads, Google Cloud Storage, Google Analytics 4, Amazon S3, YouTube, Google Ads, and many more. Beyond these native options, an additional 400 connectors are available through a library of partners. The ability to automate these transfers saves valuable engineering time and resources, ensuring your BigQuery datasets are always up-to-date and ready for analysis.
Challenge
Set up a BigQuery Data Transfer Service for a data source that you use.
*This could be as simple as copying a BigQuery dataset on a scheduled basis from another project or doing something a bit more complex like setting up a Facebook Ads connection where quite a bit of permission groundwork has to be done to get the data flowing.
Resources
https://lnkd.in/dBbx37a2

Day 27 - Table Functions
Table functions (also known as table-valued functions) provide a powerful way to query underlying data, similar to a view. However, a key advantage of table functions is their ability to accept parameters, making them much more flexible. I believe this feature, like several others we've explored in challenges so far this month, is significantly underutilized.
Challenge
Create a table function on top of the usa names public table (`bigquery-public-data.usa_names.usa_1910_current`).
This function should:
- take name as a parameter
- return a table with the total number of times that name was given each year, sorted by year in descending order.
Resources
https://lnkd.in/dRQSBEWu

Day 28 - Materialized View
oday, we're diving into the world of BigQuery Materialized Views. These pre-computed views can significantly boost your query performance and reduce costs, especially for frequently run, aggregate queries with changing underlying data.
One of the main advantages of materialized views are incremental refreshes and storage.
Incremental Refreshes - When dealing with large base tables to which data gets appended or streamed, materialized views, when called, only query data that has been added since the last run or refresh (incremental). So the outputs is up to date but only the delta is scanned.
Let's say, you're querying 1TB of underlying data that increases by 1GB every day to calculate a sum of sales per product. The initial run of materialized view would query all the underlying data, however, daily runs would only scan the 1GB change from the previous run. Since the most recent update/refresh/run, outputs have to be stored materialized views do use storage and not just query logic to exist.
Challenge
In your project (materialized view have to be in the same project or organization as underlying table), find a table with frequent row appends. Write a materialized view (code in the link in resources) that aggregates underlying data.
One example is using same-day streaming Google Analytics 4 data to obtain basic information about GEO performance.
Turn the query below into a materialized view:
CREATE MATERIALIZED VIEW `reporting.GA4_MV`
AS
SELECT
geo.country,
countif(event_name = "page_view") as page_views,
countif(event_name = "session_start") as sessions
FROM `adswerve-data.analytics_423652181.events_intraday_20250528`
GROUP BY 1
When executing materialized views, focus on bytes processed and compare them to running the actual underlying query.
Resources
Materialized Views Intro - https://lnkd.in/gtmaPQJB (image source)
Limitations: Not all SQL is allowed in materialized views. See Materialized Views query limitations for more: https://lnkd.in/gHr2CUnd
* There is a lot more to Materialized Views than the incremental use case described above. Additional features include refresh intervals, staleness configuration, non-incremental definitions... Read more in the resources to learn everything this nifty feature is capable of.
Day 29 - BQ + Looker Studio
Looker Studio, a powerful and free visualization tool, offers seamless integration with BigQuery. While simple visualizations could be achieved with a single click like we saw on day 2 https://lnkd.in/dxrccCns, getting your customized BigQuery data into Looker Studio for deeper analysis is just a two-click process (Open In --> Looker Studio).
Challenge
It's time to bring data to life in Looker Studio! Using the provided BigQuery query on public New York City taxi rides, create visualizations that showcase:
- The average fare amount across different hours of the day.
- Frequency of rides by hour of day
Feel free to try and replicate the charts in the second screenshot, or get creative and visualize other metrics to unearth unique insights into NYC taxi trips.
SELECT
FORMAT_TIMESTAMP("%A", pickup_datetime) as day_of_week,
FORMAT_TIMESTAMP("%H", pickup_datetime) as hour_of_day,
passenger_count,
trip_distance,
fare_amount,
tip_amount
FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022`
*Pay attention to data quality. Trip distances can be surprisingly high.
More Tips
Be careful when dealing with larger amounts of data, refreshing your report or changing filters execute a query for each widget on the page.
Resources
Analyze data with Looker Studio - https://lnkd.in/dZeVa_X4
Day 30 - Data Canvas
Today, we're diving into Data Canvas, BigQuery's interactive visual workspace. Data Canvas enables you to build directed workflows, run queries, join tables and query outputs, visualize data, and generate textual insights, all by using natural language prompts and a graphic interface (of course, traditional SQL is still an option).
See the short video below where I used the table from yesterday's challenge to create a query, visualize the outputs, and asked Gemini to generate insights.
Challenge
Use a public or own table. I used `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2021` to create at least 5 nodes in the Data canvas. Make sure to try writing queries, visualizing outputs, generating insights and joining tables (maybe with 2020 data for comparison).
Day 31 - Data preparation
Data Preparation in BigQuery is a powerful, Gemini-driven feature designed to streamline your data workflow. It intelligently analyzes your data, offering suggestions for cleaning, transforming, filtering, and enriching it.
All of this happens within an intuitive, easy-to-navigate UI directly in BigQuery. Much like Data Canvas (which you might know for its exploratory analysis capabilities - https://lnkd.in/dmvhHv-3), Data Preparation is an integrated BigQuery tool that you can guide using natural language. However, while Data Canvas helps you explore, Data Preparation focuses on getting your data ready for analysis.
To get started, simply select the "Open in Data preparation" option for your chosen table.
Challenge
Open Data preparation for bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022 public table.
And execute the following steps:
0. Review and apply some of the suggested transformations.
1. Transform the pickup_datetime and create additional fields for the hour of day and day of the week of pickup.
2. Apply filters to only include trips longer than 1/4 of a mile and less than $250 in cost.
3. Create a destination in your own project
4. Run the applied steps
Resources
https://lnkd.in/dwWWjHV3

