So if you've stumbled across this page you might be wondering, "Why are my users different across GA and BQ? Sessions and other metrics are fine…but users are off!"
Let's Compare
If you're using standard SQL, your query for users should look something like this:
SELECT
COUNT(DISTINCT fullVisitorId) as Users
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_20170601`
Now, comparing some metrics from the Google's demo GA account and the corresponding BigQuery dates for June 2017…
SELECT
SUM(totals.visits) as Sessions,
COUNT(DISTINCT fullVisitorId) as Users,
SUM(totals.pageviews) as Pageviews
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_201706*`
WHERE
date
BETWEEN
'20170601'
AND
'20170630'
We get this in BigQuery: 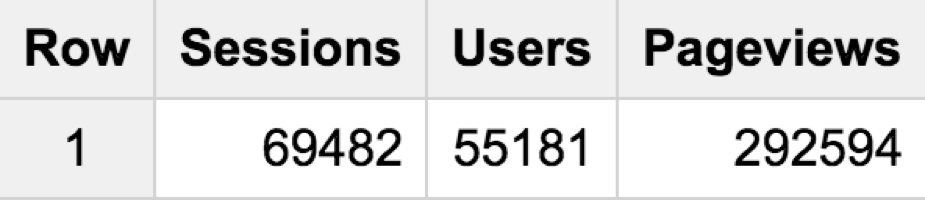 And this in Google Analytics:
And this in Google Analytics: 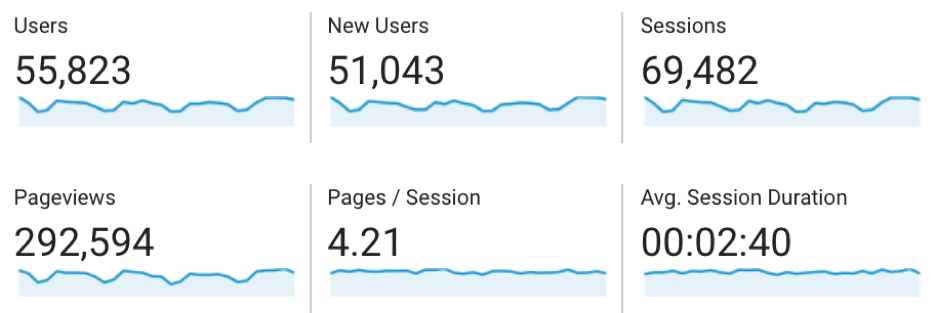 Users is only 1.2% off, but for a perfectionist, it's 100% annoying. You can breathe easy because there is a perfectly rational explanation.
Users is only 1.2% off, but for a perfectionist, it's 100% annoying. You can breathe easy because there is a perfectly rational explanation.
Google Analytics Estimates Users in GA
Google relies heavily on pre-aggregated tables in order to serve you data in a timely, efficient manner. If I'm looking at sessions or pageviews from June 1st – June 30th , Google may serve this data onto standard reports from a pre-aggregated monthly table. But If I change the dates to June 1st – July 1st , GA can simply add the sessions or pageviews from a daily pre-aggregated July 1st table to the sessions and pageviews from the previous June table. However, the users calculation don't work in the same way. It' s the count of distinct visitors based on their client ID. One can't simply add users for June and the users for July 1st and get total users. It requires a full recalculation over the full range of dates in order to accommodate for returning visitors. 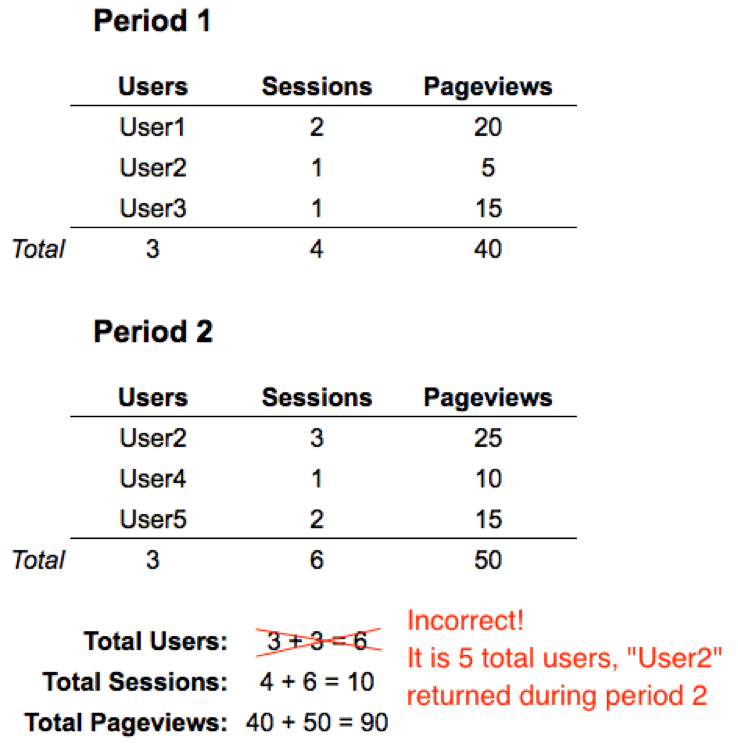 Since calculating unique users is rather resource-intensive, and they don't want to leave their users waiting for reports to load all day, Google uses an improved version of HyperLogLog (HyperLogLog ++), a probabilistic cardinality estimation algorithm. The algorithm can typically approximate distinct elements within 2% error. They use this for many of the primary reports; however you can still get a total accurate user count in unsampled reports. Speed Test HyperLogLog++ in BigQuery You can speed test HLL++ in BigQuery if you like. Try the full calculation first on the Github public data:
Since calculating unique users is rather resource-intensive, and they don't want to leave their users waiting for reports to load all day, Google uses an improved version of HyperLogLog (HyperLogLog ++), a probabilistic cardinality estimation algorithm. The algorithm can typically approximate distinct elements within 2% error. They use this for many of the primary reports; however you can still get a total accurate user count in unsampled reports. Speed Test HyperLogLog++ in BigQuery You can speed test HLL++ in BigQuery if you like. Try the full calculation first on the Github public data:
#standardSQL
SELECT COUNT(DISTINCT actor.login) exact_cnt
FROM `githubarchive.year.2016`
Query complete (5.7s elapsed, 3.39 GB processed)
Now try APPROX_COUNT_DISTINCT (which uses the HyperLogLog++ algorithm).
#standardSQL
SELECT APPROX_COUNT_DISTINCT(actor.login) approx_cnt
FROM `githubarchive.year.2016`
Query complete (3.1s elapsed, 3.39 GB processed)
You have an approximation with an error of only ~0.5% and in ~55% of the time.
Conclusion
If you're finding a small discrepancy between GA users vs. BQ users, just know that you're probably comparing your perfect BigQuery user calculation to a close, but not exact, approximation in GA. And if you want the warm feeling of reassurance, export an unsampled report in GA and you'll see that the number do in fact match.



