
Share



A lot has been done in recent years to allow data scientists to build models easily and efficiently within Google Cloud Platform. Anyone in the digital analytics space who has played with BQML knows how easy it has become to develop a proof of concept model, store predictions in BigQuery, and optionally import them to Google Analytics (GA) for some great activation options.
It all rests on the GA export to BigQuery that we all know about, and the main idea is to wait until new GA data is exported, make a prediction on the new data and activate. Essentially, the prediction part happens on the backend when the user session is over. All predictions are made after the user’s session is done and available in BigQuery.
This works well for a lot of activation use cases, the classic one being remarketing, but what if we want to “intelligently” intervene while the user session is in progress? What if we want to predict how likely it is that the page a user just loaded will be their last of the session?
This, of course, is not the only use case we can think of for client-side real-time predictions, but definitely an intriguing one because it offers a ton of actionable possibilities. For example, knowing when a user’s session is about to end can help us re-engage the user in different ways:

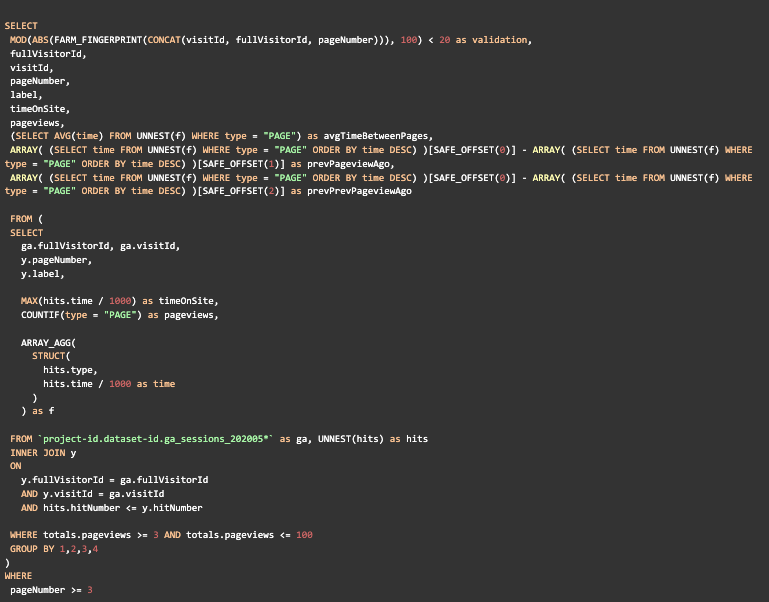 This query returns our features, which look something like this:
This query returns our features, which look something like this:
 Now it’s time to train the model. We’ll be using Tensorflow’s neural network wrapper called Keras, which makes it very easy to construct a neural net.
Below is a quick Python snippet that creates a simple neural network with two hidden layers, it accepts our five features and outputs a single number between 0 and 1:
Now it’s time to train the model. We’ll be using Tensorflow’s neural network wrapper called Keras, which makes it very easy to construct a neural net.
Below is a quick Python snippet that creates a simple neural network with two hidden layers, it accepts our five features and outputs a single number between 0 and 1:
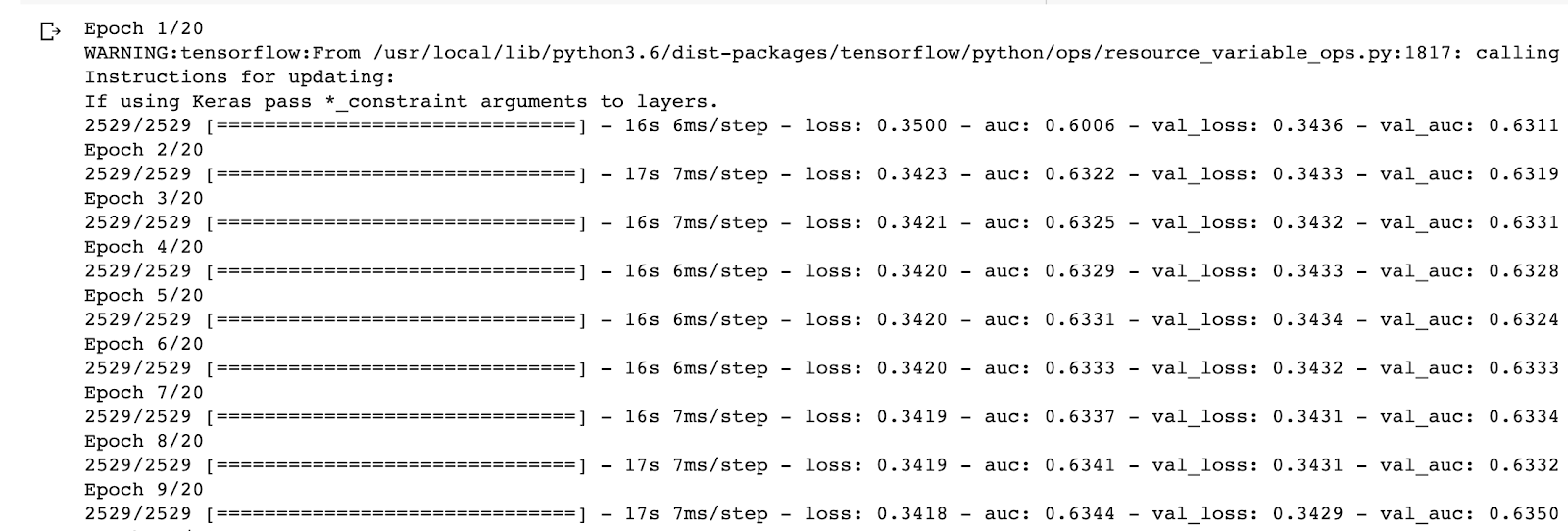
 Once the model is trained, we get an AUC score at around 0.63, which is not great, but considering we did almost none of the feature engineering this can be regarded as a very solid result, certainly much better than random.
Once the model is trained, we get an AUC score at around 0.63, which is not great, but considering we did almost none of the feature engineering this can be regarded as a very solid result, certainly much better than random.
 Assuming tensorflow js library is loaded in your browser, this line (Javascript) should be a quick test if the model loads correctly:Make sure to enable Cross-Origin Resource Sharing (CORS) for your bucket so it can be requested from your domain.
Assuming tensorflow js library is loaded in your browser, this line (Javascript) should be a quick test if the model loads correctly:Make sure to enable Cross-Origin Resource Sharing (CORS) for your bucket so it can be requested from your domain.
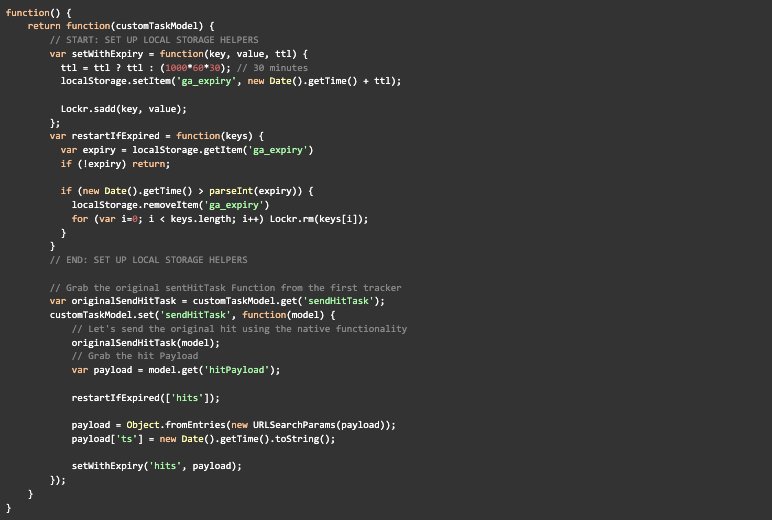 This code can be put into a Custom Javascript Variable and set as a custom task. It successfully saves all outgoing hits into local storage where we can easily retrieve them and construct our features. The code also handles session timeout, meaning if there is a 30-minute period of inactivity, the next hit will automatically be regarded as the first hit of a new session. This is needed in order to mimic the GA session timeout and to align our hits collection with how sessions are constructed in GA.
This code can be put into a Custom Javascript Variable and set as a custom task. It successfully saves all outgoing hits into local storage where we can easily retrieve them and construct our features. The code also handles session timeout, meaning if there is a 30-minute period of inactivity, the next hit will automatically be regarded as the first hit of a new session. This is needed in order to mimic the GA session timeout and to align our hits collection with how sessions are constructed in GA.
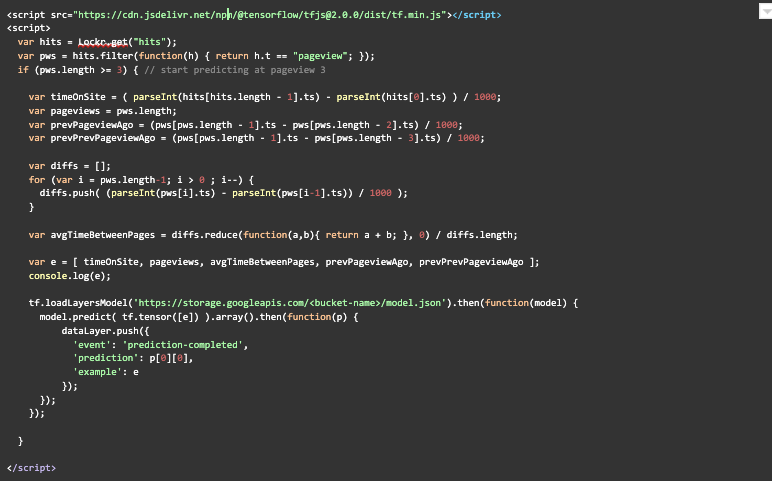 Once we have the features calculated, we use the saved model to make a prediction and push the prediction to the data layer where it can be used anywhere inside GTM.First, we load the tensorflow javascript library to give us access to the model loading capabilities. Then, we start constructing the features based on the hits collection we have stored in the local storage. Javascript is not the best when it comes to wrangling data, but with a little effort we can construct every feature required and put them in an array the same way we previously did with BigQuery.
Once we have the features calculated, we use the saved model to make a prediction and push the prediction to the data layer where it can be used anywhere inside GTM.First, we load the tensorflow javascript library to give us access to the model loading capabilities. Then, we start constructing the features based on the hits collection we have stored in the local storage. Javascript is not the best when it comes to wrangling data, but with a little effort we can construct every feature required and put them in an array the same way we previously did with BigQuery.
- Give them a coupon if there is at least $X in the cart
- Give them a time-sensitive offer
- Show recommendations that might be interesting to the user to keep them on the website
- Build and validate the model in Python using Tensorflow
- Convert the trained model to Javascript and host it so it can be served on the web
- Build up the client-side part (browser part) of the solution (data collection and prediction)
Build and Validate the Model in Python using Tensorflow
First we need to figure out where to get the training data, but the answer is pretty obvious; it’s GA export to BigQuery. It makes all the raw data available to us down to every single hit including all pageviews and events, so all we need to do is write a query with some features and a target variable we want to predict. We’ll keep it extremely simple with the features and only use five basic ones:-
- timeOnSite
- Time on site from the first pageview until the last
- pageviews
- Number of pageviews from the start of the session until now
- avgTimeBetweenPages
- The average time in seconds between all pages visited so far
- prevPageviewAgo
- Time in seconds between the previous and current pageview
- prevPrevPageviewAgo
- Time in seconds between the current pageview and 2 pageviews ago
- timeOnSite
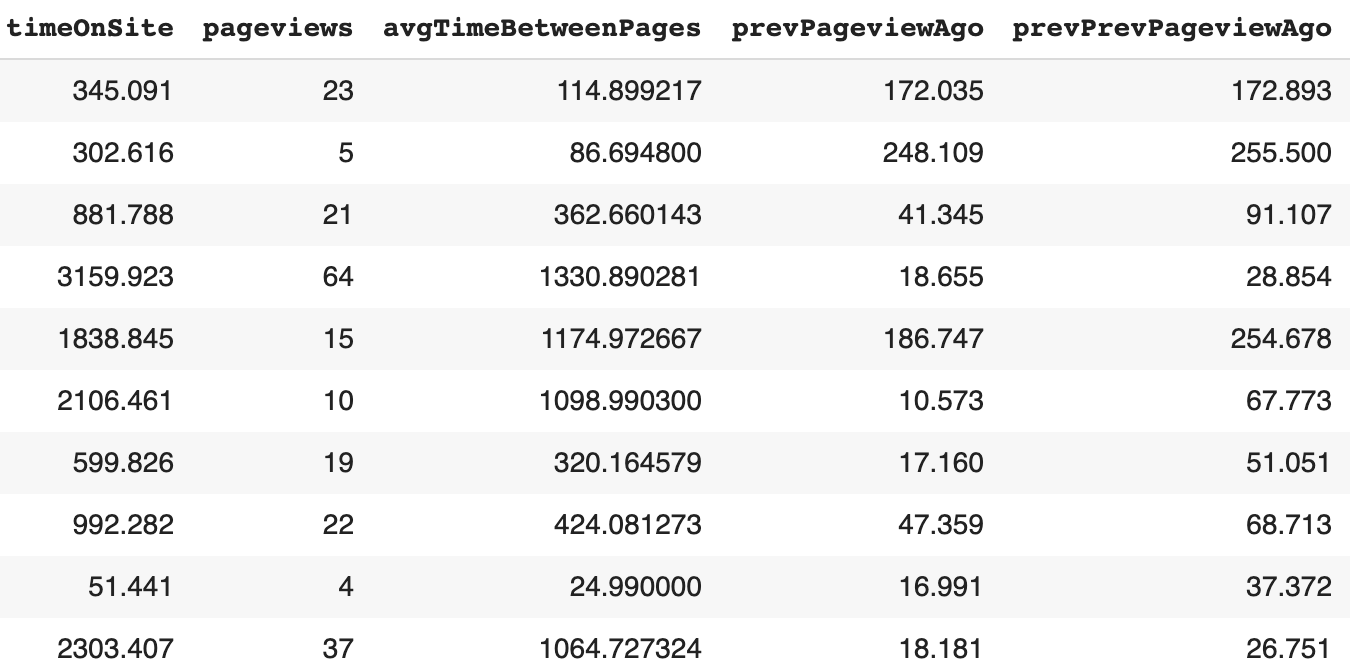
This query returns our features, which look something like this:
Now it’s time to train the model. We’ll be using Tensorflow’s neural network wrapper called Keras, which makes it very easy to construct a neural net.
Below is a quick Python snippet that creates a simple neural network with two hidden layers, it accepts our five features and outputs a single number between 0 and 1:
Once the model is trained, we get an AUC score at around 0.63, which is not great, but considering we did almost none of the feature engineering this can be regarded as a very solid result, certainly much better than random.
Convert the Trained Model to Javascript and Host It
We trained the model in the previous step so now it’s time to convert it and host it somewhere where we can later download it from the client-side. The conversion part can be done just with a two lines of code (Python):This code will save the model in the root directory, but before you run it make sure you have installed tensorflowjs Python package ( pip install tensorflowjs ). There are two parts to the exported model:

- model.json
- Contains all the neural net structure
- Weight information files
- Contain weight information for the neurons
Assuming tensorflow js library is loaded in your browser, this line (Javascript) should be a quick test if the model loads correctly:Make sure to enable Cross-Origin Resource Sharing (CORS) for your bucket so it can be requested from your domain.
Build Up the Client-Side Part of the Solution (Data Collection and Prediction)
This might be the most complex part of the solution, especially if you are not very familiar with the way GA and Tag Manager work. There are two key things we need to ensure on the client-side to be able to trust our model’s performance as validated in Python. First, we need to be able to collect all the GA hits and persist them throughout the user's session. This leads to the second thing, which is we need to make sure our feature construction process produces the exact same features we had in Python/SQL so when they’re fed to the model, they produce the correct prediction. We’ll show you how to solve both of those problems with GTM, but the same ideas should be applicable with other tag managers as well.Data Collection
The idea is to intercept each GA hit and save it to local storage before it’s sent out. We can do this with the help of a GA custom task that gives us the ability to perform actions right before the hit is sent out.
This code can be put into a Custom Javascript Variable and set as a custom task. It successfully saves all outgoing hits into local storage where we can easily retrieve them and construct our features. The code also handles session timeout, meaning if there is a 30-minute period of inactivity, the next hit will automatically be regarded as the first hit of a new session. This is needed in order to mimic the GA session timeout and to align our hits collection with how sessions are constructed in GA.
Prediction
The very last step is to make the actual prediction. Again, the most important part here is to make sure the features are constructed in the same way as in the training model part, only this ensures we can trust them. The below code can be put into a Custom HTML tag and triggered after each page load.
Once we have the features calculated, we use the saved model to make a prediction and push the prediction to the data layer where it can be used anywhere inside GTM.First, we load the tensorflow javascript library to give us access to the model loading capabilities. Then, we start constructing the features based on the hits collection we have stored in the local storage. Javascript is not the best when it comes to wrangling data, but with a little effort we can construct every feature required and put them in an array the same way we previously did with BigQuery.