
Adobe Analytics gets a lot of love from its users for its deep feature set, ability to explore clickstream data and curate self-serve reports and dashboards. Yet when it comes to the person responsible for the Adobe Analytics contract (especially finance), if you ask what gives them heartburn, you’ll get an almost unanimous answer: server calls.
No matter how robust your model, how thorough your server call audit or how big of a buffer you bake into your contract, there always seems to be something to derail your server call budget. A runaway site monitoring bot. Scroll tracking that triggered four milestones on page load that no one found for a month. Or, that new widget that went viral after an influencer mentioned it. Now, you’re crawling back to your leaders and procurement to approve an(other) overage.
With all of the airtime Adobe gives to Customer Journey Analytics (CJA), you have very likely heard about the benefits of its first-party data and cross-channel capabilities. Less discussed is how CJA can also handle most Adobe Analytics use cases, while using modern data platform capabilities and a new licensing model to put to bed angst associated with server calls.
For those needing a refresher, a server call represents every event sent from your website or mobile app to Adobe’s collection server. In contrast, Adobe Customer Journey Analytics uses the number of rows or events that are available for use (or “reportable”) in CJA. Big whoop, right? They may sound similar, but the difference is significant.
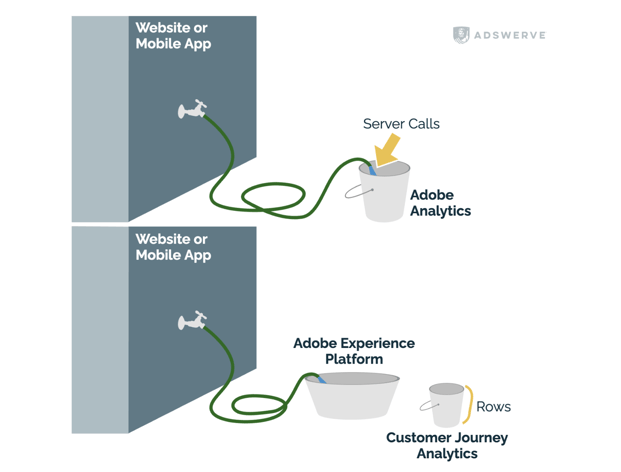
Think of your website and the flow of events coming from it as a spigot. When you purchase Adobe Analytics (AA) and tag your site, you connect a hose to it and turn on the events that flow directly into Adobe’s servers. With AA, you pay for everything that comes from the hose, regardless of what it is. If a bunch of gunk (e.g., bots, QA data) unexpectedly starts coming out, your primary option is to turn off the spigot (i.e., turn off your tag). Otherwise, you have to start an investigation with IT or purchase tools to prevent the gunk from getting in the hose. And you still have to pay for the gunk that already came out.
With CJA, that hose of events goes into the Adobe Experience Platform (AEP) data lake first. Adobe includes access to AEP with every CJA license. In our analogy, it’s a trough to dump data into first. When configuring CJA, you pick and choose which events from AEP you’ll bring into CJA. If there’s gunk in AEP, you can remove it and the updates cascade to CJA. Every quarter, the number of reportable events in CJA is averaged and considered your contracted “rows.” In other words, in AA you pay for what comes out of the hose and with CJA you pay for the size of the bucket.
The result is far more value-based, incentivizing data quality over quantity. With the “rows” model, you have a handful of options to control and curate the data that appears in CJA and ultimately hits your budget. Here are four of those critical levers.
Four Critical Levers to Curate Data for CJA
CJA Connection: Rolling Data Windows
Level of complexity: Low
Level of control: Medium
License considerations: None
Your first line of defense is a blunt but effective option to avoid overages. If row counts run up against your contract, CJA allows you to dial forward a Connection’s retention to effectively purge the oldest data from the CJA bucket. The underlying data remains in AEP and you can bring it back in if you renegotiate or free up rows. Keep in mind that if you have multiple datasets in a single Connection, all of the datasets will share the same retention.
AEP APIs: Dataset Pruning
Level of complexity: Medium
Level of control: Medium
License considerations: Foundation SKU does not have ad hoc Query Service access
Unlike the first option that changes data in CJA, this is a permanent change in the AEP data lake, so use it carefully. As mentioned above, the Connection level retention in CJA is uniform across all datasets. Utilizing the AEP Batch Ingestion API, you can manually remove older batches from AEP datasets.
For example, let's say you want to bring in high-volume impression data and only have use cases for the prior six months, but you want to keep your other website data at a 24-month retention in the Connection. You could use Query Service to retrieve the batch IDs (_acp_system_metadata.acp_sourceBatchId) older than six months, then use the API to delete those batch IDs. Again, this one is permanent, so use it carefully, but it can help you more precisely manage retention.
Coming Soon: Data Lifecycle “delete records” capabilities may help simplify this task, eliminating the need to retrieve batch IDs via query.
AEP Query Service Data Distiller
Level of complexity: Medium
Level of control: Medium
License considerations: Requires Data Distiller Add-On SKU
Data Distiller encompasses the SQL commands within Query Service required to transform existing data and schedule them to be completed on a regular cadence in AEP. The functions it enables generally require a more advanced level of SQL skills. If you’re familiar with the Data Repair API in AA, Data Distiller addresses those use cases and more. Some potential options to control rows include:
- Storing raw event collection in a separate dataset than the one used for CJA. This can allow you to run hourly batch queries to cleanse and filter the raw data and output a clean dataset for CJA. The downside is the introduction of additional latency for end users, but in the context of customer journeys, cleaner data can often provide more value than fast data.
- Running an archiving process on your data that moves it from an ongoing dataset to a historical one. As part of the archiving, you can apply bots and other filters. With this approach, you’d have to be diligent about creating filters at the Data View to ensure that the bots excluded as part of the archiving process are similarly excluded from your ongoing dataset to prevent big shifts after the archive process runs. One downside for this option would be that you would have to process all your events into CJA two times: once for the initial ongoing ingest and again for archiving.
- One-off data cleansing tasks to remove unwanted QA data, bots or sensitive PII. This can be achieved by running a query on the affected time period and using the Create Table As (CTAS) function to save a new table with the clean data. Then, with the above batch removal process, you can remove the bad batches and bring the clean ones back in.
These examples scratch the surface of what’s possible with SQL transformation and scheduling. Adding Data Distiller is a substantial upgrade in how you can control your data within the walls of AEP.
Capturing Events in an External Cloud
Level of complexity: High
Level of control: High
License considerations: None
Lastly, the most flexible approach you can take to control how many rows are consumed is to collect your events outside of Adobe in another cloud platform. While this can be a major change in how you collect and use digital analytics data, it provides maximum control over what you choose to put into AEP. Unsurprisingly, it also requires the most resources and careful planning. This is actually possible with Adobe Analytics via APIs, as well, and used by a small number of AA users, but the AEP source connectors and schemas have made this architectural pattern even more accessible and convenient for CJA.
Advantages:
- It gives you full control over the filtering of bots or other unwanted data
- You can transform data, including the ability to stitch identities across events
- You can collapse separate events (impressions, scroll tracking, etc.) into single events to optimize row count.
- When an event occurs, you can enrich it with other data within your cloud data warehouse, such as product, company or demographic information.
Disadvantages:
- You need significant data engineering resources to build and maintain pipelines.
- It may impact latency due to additional hops across platforms, performing transformations and applying filters.
- You need to be aware of storage and consumption costs within cloud platforms. Without oversight and optimization, these can exceed any potential savings.
- IP and User Agent enrichments are built into the Edge Network and ingest into AEP, so those either need to be recreated or ingest must be routed through the Edge Network Server API.
- The approach can impact real-time personalization use cases with other Adobe products, depending on how you implement it.
Regardless of the approaches you take to curate your data, the fact that you have options is a refreshing change of pace. Your finance and procurement partners will value the stability and predictability. Costs can and will go up, but the looming threat of overages should be more manageable and you’ll be able to forecast and plan for increases using the levers afforded to you in AEP.
Additional Pricing Model Considerations
There are a few stipulations and guardrails that Adobe has put in place to prevent customers from taking advantage of the rows pricing model:
- When getting to the contracting details, CJA rows are broken into two buckets. The first is the current rolling 13 months and is considered your CJA licensed rows. A second bucket can be purchased with an add-on SKU for events older than 13 months. Keep this in mind when deciding how much history you want to make available in CJA.
- To keep you from cramming too much into a single row, the average row size can’t exceed 2 KB. A typical web or mobile implementation generally stays under 1 KB per event.
- There’s a limit of 3X your contracted rows that can be ingested into CJA in one year. This could become relevant if you frequently remove data, clean it and reload it.
- AEP storage is limited to 5 KB per contracted row in CJA. The longer you're using AEP, the more important it will be to make sure you remove unnecessary data in AEP. As you start making copies of large event datasets, the gigabytes can quickly start turning into terabytes. An additional AEP storage add-on SKU is available to expand storage if needed.
Adobe is in the business of making money, so they’ll continue to evolve how they license their products to make sure they’re profitable. The details from contract to contract can differ, so always read the fine print and be open about how you plan to bring data into CJA during the negotiation process. For example, if you plan to create a process with Data Distiller that prevents bots from being brought into CJA as rows, be transparent, and Adobe can make sure you have the capacity within AEP to facilitate that approach.
Finally, Adswerve has extensive experience helping Adobe customers get the most out of their analytics investment. Some of these options require consulting and licensing expertise, which we can support. If you’re struggling with runaway server calls or looking to optimize a CJA implementation, schedule a 30-minute consultation, and we can help get it under control.
