
While the Experience Data Model (XDM) schema within Adobe Experience Platform (AEP) has proven powerful at enabling Adobe’s products to share data from the platform in a common data model, its open-ended design has thrust marketers and analysts into the unfamiliar role of amateur data modeler. With limited experience modeling data, the task can be intimidating and result in mistakes that can impact the value of data for years to come.
Adobe has documentation to help with the exercise; however, it can feel a little like being thrown into the deep end of the pool. Additionally, web and mobile digital analytics data can be a unique beast that can cause even more complexities. With this article, we hope to equip you with the knowledge and best practices to help you be a good steward and maximize the value of your organization’s digital data in Adobe Experience Platform.
What is Data Modeling?
A data modeler designs databases to efficiently access and use data for business processes. It may not always seem clear in AEP’s self-service user interface, but under the hood, this is the role enabled by XDM. In fact, with support for objects and nested arrays, the resulting tables can be complex enough to give even the most experienced data modeler heartburn. Without standards and best practices, AEP’s data lake can quickly become the dreaded data swamp.
XDM Schema 101
Adobe has taken a unique approach that doesn’t fully adopt some of the traditional principles of modeling data with SQL. Instead, they have applied a framework called XDM. To understand the XDM schema, we’ll first need to cover some key terms.
At the most basic level, a schema is a defined list of fields. The fields should combine to describe a real-world object or experience as a data structure. Additionally, it serves as a contract to guarantee that incoming data follows a consistent and defined format with basic validation for each field (data types, lengths, etc.).
AEP additionally applies the concept of a class to assign schemas a set of required fields that inform Adobe products whether the data contained within that dataset will be compatible with that product. For example, Customer Journey Analytics (CJA) expects at least one dataset with a schema class of XDM Experience Event due to the required timestamp utilized for reconstructing journeys. Classes are the primary way to identify the three main types of datasets expected to exist in AEP:
- Event
- Profile
- Lookup
Building a Schema with Field Groups
Also, unique to AEP, fields are created inside field groups to encourage the reuse of commonly combined fields and to standardize schema creation. You may see documentation or API references to “mixins”, which was an early name for field groups that was eventually replaced in the user interface.
Adobe has made a number of pre-built, standard field groups available. While these field groups may help with some very basic attributes that you will collect along a customer journey, they are not comprehensive and will miss critical fields needed for many web and mobile experiences (e.g., forms, navigation, errors, etc.). Additionally, they will often contain extraneous fields that will be unnecessary for your implementation. As a result, almost every implementation will involve a considerable amount of custom field group creation, which is where the bulk of your newfound data modeling skills will become handy.
Standard or Custom Field Groups
The hardest decision point when designing XDM schema is if and when to leverage the Adobe standard field groups. What are the differences between standard and custom field groups?
Standard Field Groups
- Preloaded by Adobe and made available as part of their vision to create a unified data model
- May enable automated functionality (e.g., device lookups on Datastreams via Edge Network)
- Appear at the root level of a schema
Custom Field Groups
- Manually added by an Adobe customer
- Appear within a “_tenant” namespace object at the root (where “tenant” is replaced with your organization’s name)
- Allow full control over which fields to include, as well as ensuring that naming matches internal terminology and semantics
Additionally, there is an ability to extend a standard Field Group with custom fields, creating a hybrid field group. This approach allows you to add custom fields to standard objects without having to use the “_tenant” namespace.
It can be helpful to think of field groups as data building blocks that can be stacked to create schemas. In the below example, we have a retail experience in which a customer can navigate a website and make purchases. There are two datasets intended to be used in Adobe CJA: website clickstream data and transactional data from a back-end order management system.
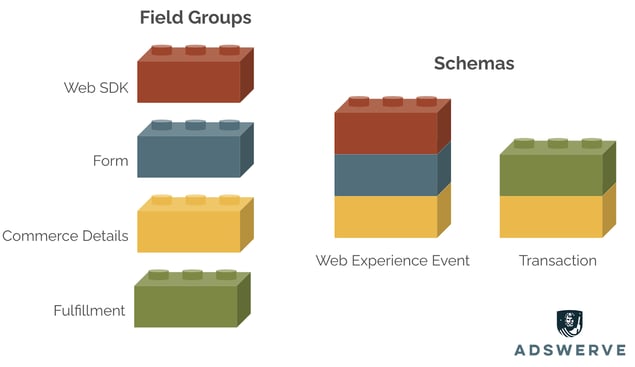
You can see a standard Commerce Details field group block that exists across both schemas. The common field group is essential for reporting on fields across these datasets in a continuous way. For example, a use case may be to analyze whether products with certain behaviors on the website (e.g., viewing a video, reading reviews, etc.) are less likely to cancel or return an order. If the schemas are constructed with mismatched blocks, they won’t be able to correlate the product activity from the website to the outcomes in the transaction dataset.1
1 There are options within Adobe CJA to work around the ‘mismatched blocks’ scenario with Derived Fields, but it should only be considered as temporary until the data model can be updated appropriately.
Planning Ahead to Avoid Breaking Changes
As you dive into creating your first schema, it is important to be aware of breaking changes and their impact on schema design choices. As your business grows, your schema can and should grow, too. Any modification that could cause existing data stored against the schema to become non-conforming is considered a breaking change and is strictly not allowed. If you haven’t collected data yet, you can make any changes you need. Once that dataset is populated, you will be subject to breaking changes, which include, but are not limited to:
- Field path changes, including field name (Display name can change at any time)
- Data type changes
- Field deletions
- Changing an optional field to required
If you need to make one of these breaking changes, you will have to create an entirely new schema and reprocess your data to conform to the new schema—a painful process no one wants to endure. For that reason, you will want to be deliberate about additions to your schema, as once data is stored against it, there are limited options for going back.
Data Modeling Best Practices
While following standards and best practices provides a foundation for governance and compliance, it’s just as much about improving the user experience for data consumers. The more uniform and consistent the data is, the easier it is to explore and contextualize. Just as you want a digital experience to be effortless and intuitive to use, working with data should be no different.
Now that you have a basic background on AEP schemas let's get down to some best practices. As this guide is more focused on web and mobile behavioral data, these recommendations will be aimed at those types of data structures. That said, a lot of these principles do apply to any type of data in AEP.
- Use Adobe-owned field groups as a starting point. The standard AEP Web SDK ExperienceEvent (web and mobile apps) and AEP Mobile Lifecycle Details (for mobile apps) field groups align to automated functions within Adobe’s data collection tools. If using AEP Data Collection, take advantage of those and use them as a starting point for your web and mobile datasets. The specific objects that will be populated by the automated collection, when enabled, are:
- placeContext (Web SDK)
- environment (Web SDK and Mobile Lifecycle)
- device (Web SDK and Mobile Lifecycle)
- application (Mobile Lifecycle)
- Within the standard field groups, don’t populate them just because they’re there and remove them if you won’t use them. If you find that one of the standard field groups aligns with your data needs, there will often be excess fields that you don’t need for your use cases. There is an implementation and maintenance cost for every field you choose to populate. Pick the fields that provide the most value for your business and remove the rest.
- Don’t sacrifice semantics to adhere to the standard field groups. If it isn’t clear to you what a standard field is supposed to be and it isn’t auto-generated, don’t use it. Opt for custom field groups or extend the standard field group when a standard field doesn’t make sense for how your business talks about the data (e.g., create a custom cartAdditions instead of using productListAdds). As long as a field isn’t system-generated, it will benefit your users to have clear, understandable fields instead of ambiguous and force-fit fields to meet the standard.
- Don’t overload a single field with multiple types of data in delimited or concatenated strings. Normalize the data in separate fields or in an array if it’s a list. This will ensure that policies can be applied at the field level and data is protected appropriately.
- Don’t create website, app or dataset-specific field groups for schemas. Organize field groups by the real-world objects and entities they are meant to represent. Those will likely repeat across your schemas and reusing common field groups will ensure that data aligns across datasets and that schema updates cascade to each of your schemas.
- Create one large schema for web and mobile datasets, similar to a Global Report Suite. There can be exceptions to this, but generally, having fewer schemas to maintain will be better. Additionally, keep your license structure in mind. For example, CJA Foundation currently allows only one event dataset per Connection. Creating a separate schema and dataset for every site may prevent you from bringing all of the data together in CJA.
- Don’t create field groups for a vendor/tool. Instead, organize them by the generic real-world object or experience they are meant to describe (e.g., leads, marketing campaigns, appointments, etc.). This will allow you to reuse them across schemas and datasets.
- Make sure that commonly occurring fields (e.g., SKU id, location id, campaign id) share the same field group in their respective schemas. If they are in different field groups and have different schema paths, the fields will mismatch when you attempt to merge them as one continuous journey.
- Do NOT create flex fields. Along the way, you may hear something to the effect of “We don’t always know what we need to collect, so can we create an array that can hold any field and value combination?” DON’T. This may seem like a clever way around having to create new fields, but it is a notorious source for data leaks. One of the purposes of schema is to label and protect fields with policies appropriate for the sensitivity of the data within it. Once a field has potentially endless meanings, it will inevitably be misused. Additionally, it is fragile and time-intensive for data consumers to have to apply logic when reading from these types of flex fields.
- Carefully consider whether to append data to a schema or use a separate lookup schema. When building out your data model, sometimes you will have data that can be captured and stamped directly on an Experience Event or be loaded in through a backend process and enriched with a lookup dataset. Be intentional about whether you choose one or both of these options. Some factors to consider:
- Fields that can change from day to day or user-to-user (e.g., price, wait time, loyalty status) are a better fit to be stamped to the Experience Event.
- Slow-changing data like product information or user demographics will be a better fit for utilizing lookups to enrich the event data. The downside of a lookup is that if data does change (taxonomy, for example), the historical representation of what it was when the event happened will be lost. If that matters for your use case, stamping it to the event may be more appropriate.
Naming Conventions
When it comes to naming conventions in data modeling, the most important thing is that you have one, regardless of the details of what it is. The conventions below primarily take a nod from the out-of-the-box field groups provided by Adobe while applying some other common conventions to help with readability. Here are some suggestions, but feel free to add on with your own:
- For field Name, use camel case (cartAdditions, mediaPlayer)
- For field Display Name, use normal spacing and capitalization (Cart Additions, Media Player)
- For field Name, don’t repeat the name of the parent object in a child field to keep schema paths readable.
- For field Display Name, include the parent object name to make it easier to find in field lists.
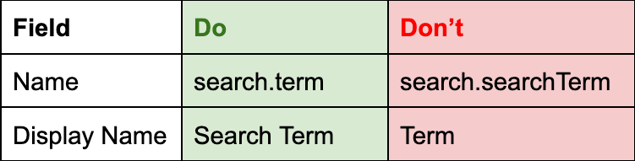 Naming convention do's and don'ts.
Naming convention do's and don'ts.
- Don’t use acronyms except for the most commonly used ones (sku, id, ip, etc.)
- Don’t use internal project names.
- Don’t use vendor or tool names except for vendor-specific IDs.
- Reserve plural field names (e.g., filters, payments, checkouts) for two types of fields:
- Arrays: whether an array of objects, strings, or other data types, plural names help data consumers understand that they are working with multiples of that field.
- Metrics or events: a convention sometimes used in Adobe field groups, these will typically be an object with two fields inside: ‘id’ and ‘value’. The ‘value’ would contain a numeric value to increment the metric, most of the time 1, while the ‘id’ would serve as an optional identifier for deduplication.
Final Thoughts
Data modeling with XDM can be overwhelming. To make it more manageable, break it into pieces. Do a trial run of your data models with sample data, and it can help you see how they come together. Most importantly, know that there is no perfect data model, but with a good foundation and focus on semantics, you can ensure that your organization’s Adobe CJA use cases can be met.
This article is the first in a series to help you lay the foundation you need to be successful with Adobe Customer Journey Analytics. Additionally, we geek out about data models and would be excited to schedule a free 30-minute consultation to discuss your implementation of Adobe CJA.
